简介
无可非议,pandas是Python最强大的数据分析和探索工具之一,因金融数据分析工具而开发,支持类似于SQL语句的模型,可以对数据进行增删改查等操作,支持时间序列分析,也能够灵活的处理缺失的数据。它含有使数据分析工作变得更快更简单的高级数据结构和操作工具。pandas是基于NumPy构建的,让以NumPy为中心的应用变得更加简单。
这里所说的让pandas变得更快更简单的高级数据结构就是Series和DataFrame。要熟练使用pandas,首先得要熟悉它的这两个主要的数据结构:Series和DateFrame。
本文将针对Series和DateFrame,介绍Series和DataFrame数据对象的创建及基于数据对象的基础上对数据进行选择、增加、删除等数据操作。
一、Series
Series是一种类似于一维数组对象,它是由一组的数据值value(各种NumPy数据类型)以及一组与之相关的数据标签index(即索引)组成,其中标签与数据值之间是一一对应的关系。
1 | import pandas as pd |
结果:
1 | 0 陈一 |
Series的字符串表现形式为:索引在左边,值在右边。由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
可以通过Series的values和index属性获取其数组表示形式和索引对象。
可以将Series看成一个定长的有序字典,因为它是索引值到数据值的一个映射。
1、Series对象创建
pandas 使用 Series() 函数来创建 Series 对象,通过这个对象可以调用相应的方法和属性,从而达到处理数据的目的:
1 | import pandas as pd |
参数说明如下:
| 参数名称 | 描述 |
|---|---|
| data | 输入的数据,可以是列表、常量、ndarray 数组等。 |
| index | 索引值必须是惟一的,如果没有传递索引,则默认为 np.arrange(n)。 |
| dtype | dtype表示数据类型,如果没有提供,则会自动判断得出。 |
| copy | 表示对 data 进行拷贝,默认为 False。 |
data可以是列表、常量、ndarray数组等,如果数据被存放在一个Python字典dict中,也可以直接通过这个dict来创建Series,如果没有传入索引时会按照字典的键来构造索引;反之,当传递了索引时需要将索引标签与字典中的值一一对应。
前面的列子是通过列表来创建的Series,接下来看下通过ndarray和dic来创建Series。
通过ndarray创建Series
1 | #ndarray创建Series |
结果:
1 | 0 陈一 |
通过dict创建Series
#通过dict创建Series,没有设置indx
1 | import pandas as pd |
结果:
1 | 1 张三 |
当传递的索引值无法找到与其对应的值时,使用 NaN(非数字)填充。
1 | #通过dict创建Series,设置indx |
结果:
1 | 1 张三 |
2、Series操作
Series数据访问
Series提供了多种数据访问的方式,可以通过位置下标及索引来访问数据,可以访问单个数据也可以访问多个数据。
通过位置下标及索引来访问数据
1 | import pandas as pd |
结果:
1 | obj的Series数据 |
head()&tail()查看数据
如果想要查看 Series 的某一部分数据,可以使用 head() 或者 tail() 方法。其中 head() 返回前 n 行数据,默认显示前 5 行数据。
1 | import pandas as pd |
结果:
1 | 输出前三行数据 |
Series数据增加
1.直接通过索引增加
1 | #通过索引增加数据 |
2.通过append()增加
1 | #通过append()增加多个数据 |
结果:
1 | 一 陈一 |
Series数据修改
Series数据可以通过制定索引直接修改
如:修改索引为十一的数据,直接obj[‘十一’]=’肖XX’,就可以进行修改。
1 | #修改Series数据 |
Series数据删除
通过drop()删除,注意如果没有带inplace=True,会返回一个新的Series对象。如果要修改本对象,注意要带上inplace=True。
1.删除单个数据
1 | obj.drop('十一',inplace=True) |
2.删除多个数据
参数为索引列表,即可以删除索引为列表中的数据
1 | obj.drop(['十二','十三'],inplace=True) |
二、DataFrame
DataFrame 是 Pandas 的重要数据结构之一,也是在使用 Pandas 进行数据分析过程中最常用的结构之一。DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。DataFrame 的每一行数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。可以把DataFrame看做是关系型数据库里或Excel里的一张表格来理解。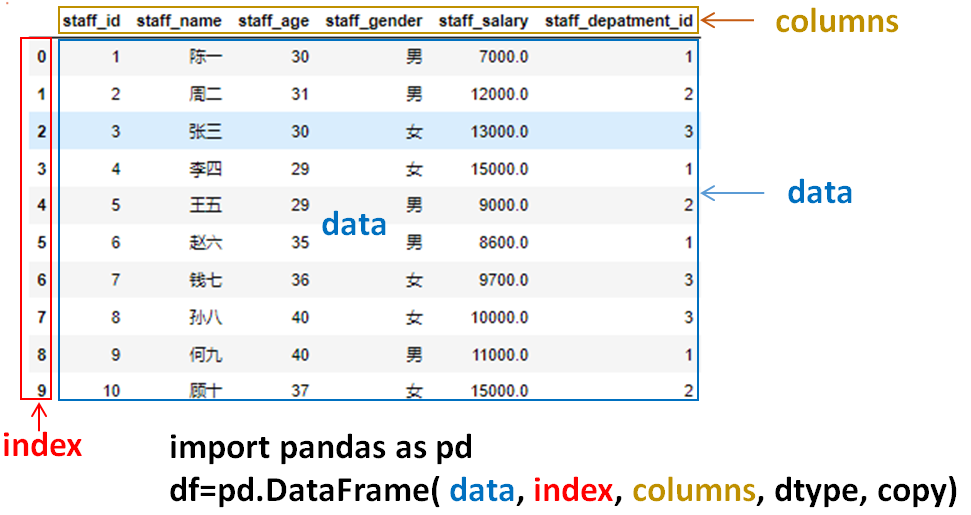
DataFrame 数据结构的特点:
DataFrame 每一列的标签值允许使用不同的数据类型;
DataFrame 是表格型的数据结构,具有行和列;
DataFrame 中的每个数据值都可以被修改。
DataFrame 结构的行数、列数允许增加或者删除;
DataFrame 有两个方向的标签轴,分别是行标签和列标签;
DataFrame 可以对行和列执行算术运算。
1、DataFrame对象的创建
1 | import pandas as pd |
参数说明:
| 参数名称 | 说明 |
|---|---|
| data | 输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。 |
| index | 行标签,如果没有传递 index 值,则默认行标签是 np.arange(n),n 代表 data 的元素个数。 |
| columns | 列标签,如果没有传递 columns 值,则默认列标签是 np.arange(n)。 |
| dtype | dtype表示每一列的数据类型。 |
| copy | 默认为 False,表示复制数据 data。 |
Pandas 提供了多种创建 DataFrame 对象的方式可以看data的参数说明,包括列表、ndarray、series、dict等。
平时在数据分析过程中用得最多的应该是从其他数据源文件如cvs、excel、数据库、WEBAPI等方式加载数据到DataFrame中。
如:从Excel中加载数据。更多的数据加载方式见:http://xiejava.ishareread.com/posts/4864590d/
1 | import pandas as pd |
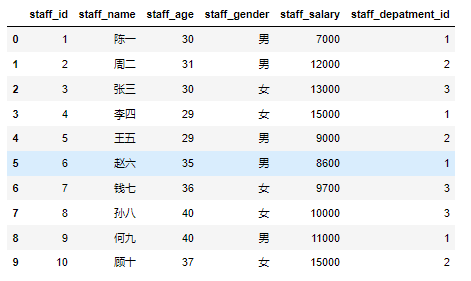
2、DataFrame数据操作
DataFrame 可以使用行索引(index )来选取 DataFrame 中的数据并进行操作。也可以使用列索(columns )引来完成数据的选取、添加和删除操作。
1) 行索引操作DataFrame
选取数据
行标签选取数据
1 | #选取行标签为2的行 |
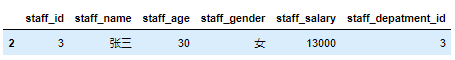
注意:如果是df.loc[2],同样是选择行标签为2的行,但现实效果为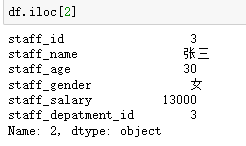
因为df.loc[2]返回是Series对象,而df.loc[[2]]返回的是DataFrame对象
1 | type(df.iloc[2]) |
1 | type(df.loc[[2]]) |
切片选取数据
1 | #切片选取数据(左闭右开) |

增加行
添加数据行,使用 append() 函数,可以将新的数据行添加到 DataFrame 中,该函数会在行末追加数据行。
1 | df_1 = pd.DataFrame([[11,'肖十一','30','女','7000','1'],[12,'郭芙蓉','30','女','7400','1']],index=[11,12],columns = ['staff_id','staff_name','staff_age','staff_gender','staff_salary','staff_depatment_id']) |
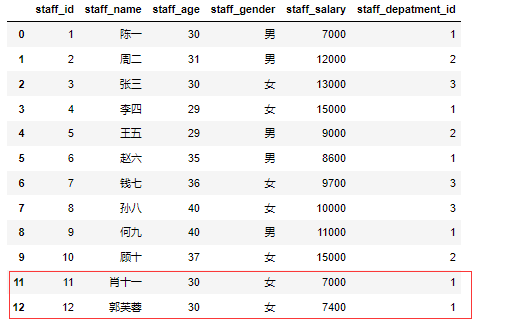
注意新增加的DataFrame如果没有指定行索引,将会默认从0开始,添加数据行后将会有行重复的行索引。如没有指定index=[11,12]
1 | df_1 = pd.DataFrame([[11,'肖十一','30','女','7000','1'],[12,'郭芙蓉','30','女','7400','1']],columns = ['staff_id','staff_name','staff_age','staff_gender','staff_salary','staff_depatment_id']) |
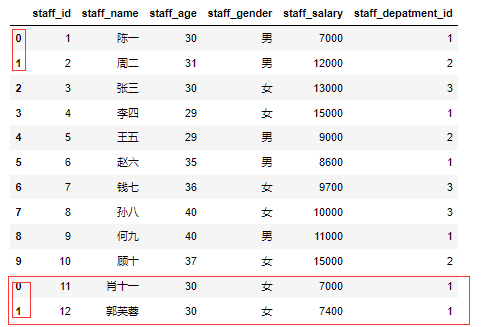
删除行
可以使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除
1 | df=df.drop(0) |
可以看到到行索引为0的两条记录被一起删除了。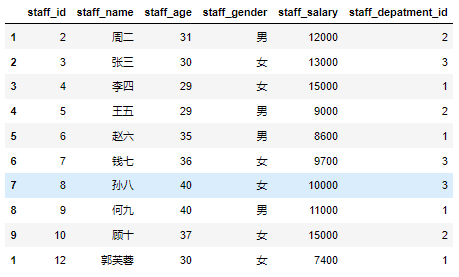
2) 列索引操作DataFrame
列索引选取数据列
通过指定列索引来选取数据列,如选择只显示staff_id,staff_name,staff_gender三列
1 | df2=df[['staff_id','staff_name','staff_gender']] |
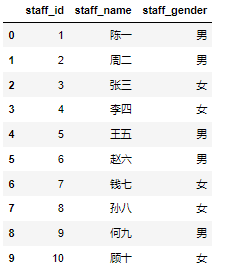
列索引添加数据列
1 | df3=df['staff_salary']+500 |
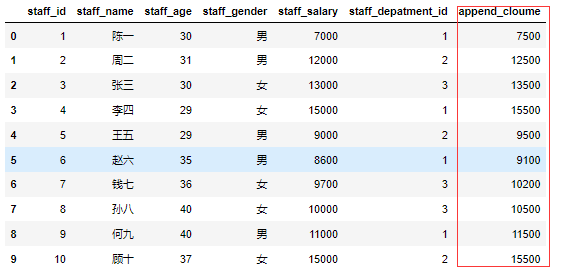
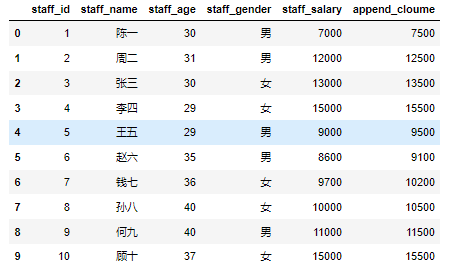
列索引删除数据列
通过del 来删除指定的数据列,如删除staff_depatment_id列
1 | del df['staff_depatment_id'] |
本文介绍了pandas的两大核心数据结构Series和DataFrame,分别介绍了Series和DataFrame数据对象的创建及基于数据对象的基础上对数据进行选择、增加、删除等数据操作,可以加深对Series和DataFrame的理解,并可以将创建,增、删、改、查等应用于实际的数据处理应用中。
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!