
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使Python成为强大而高效的数据分析环境的重要因素之一。
数据的输入是数据分析的第一步,如果不能将数据快速方便的导入导出python,那么pandas不可能成为强大而高效的数据分析环境,本文重点介绍pandas的数据输入加载。pandas的数据输入可以划分为几个大类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据,利用Web API获取网络资源。
pandas的IO工具支持非常多的数据输入输出方式。包括csv、json、Excel、数据库等。
| Format Type | Data Description | Reader | Writer |
|---|---|---|---|
| text | CSV | read_csv | to_csv |
| text | JSON | read_json | to_json |
| text | HTML | read_html | to_html |
| text | Local clipboard | read_clipboard | to_clipboard |
| binary | MS Excel | read_excel | to_excel |
| binary | OpenDocument | read_excel | |
| binary | HDF5 Format | read_hdf | to_hdf |
| binary | Feather Format | read_feather | to_feather |
| binary | Parquet Format | read_parquet | to_parquet |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | Python Pickle Format | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google Big Query | read_gbq | to_gbq |
本文通过几个实例,介绍几种常用的数据加载方式,包括从csv文件、excel文件、关系型数据库如mysql、API接口加载json数据,来初步体验一下pandas加载数据的便捷性。
见上表pandas 提供了多种数据源读取数据的方法:
read_csv() 用于读取文本文件
read_json() 用于读取 json 文件
read_sql_query() 读取 sql 语句查询的表记录
一、读取CSV文件
CSV 又称逗号分隔值文件,是一种简单的文件格式,以特定的结构来排列表格数据。 CSV 文件能够以纯文本形式存储表格数据,比如电子表格、数据库文件,并具有数据交换的通用格式。CSV 文件会在 Excel 文件中被打开,其行和列都定义了标准的数据格式。
将 CSV 中的数据转换为 DataFrame 对象是非常便捷的。和一般文件读写不一样,它不需要你做打开文件、读取文件、关闭文件等操作。相反,只需要一行代码就可以完成上述所有步骤,并将数据存储在 DataFrame 中。
pandas通过read_csv()从 CSV 文件中读取数据,并创建 DataFrame 对象。
下面通过一个实例来说明。一个用于测试的员工数据集csv的数据如下,文件为staff.csv。
1 | "staff_id","staff_name","staff_age","staff_gender","staff_salary","staff_depatment_id" |
代码如下:
1 | import pandas as pd |
输出: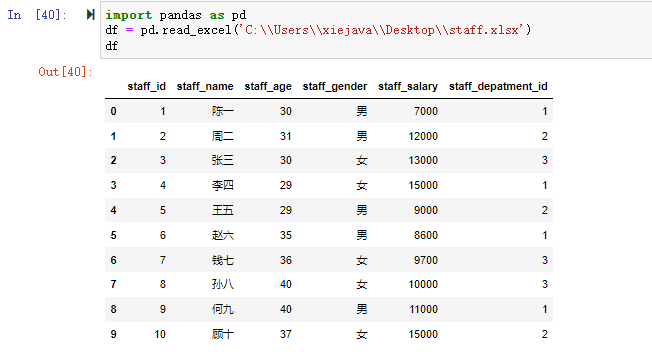
二、读取EXCEL文件
Excel 是由微软公司开发的办公软件之一,它在日常工作中得到了广泛的应用。在数据量较少的情况下,Excel 对于数据的处理、分析、可视化有其独特的优势,因此可以显著提升您的工作效率。但是,当数据量非常大时,Excel 的劣势就暴露出来了,比如,操作重复、数据分析难等问题。Pandas 提供了操作 Excel 文件的函数,可以很方便地处理 Excel 表格。
pandas提供了 read_excel() 方法,从 Excel文件中读取数据,并创建 DataFrame 对象。
staff数据集excel文件staff.xlsx如下图: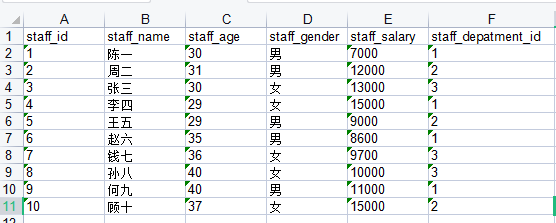
代码如下:
1 | import pandas as pd |
输出: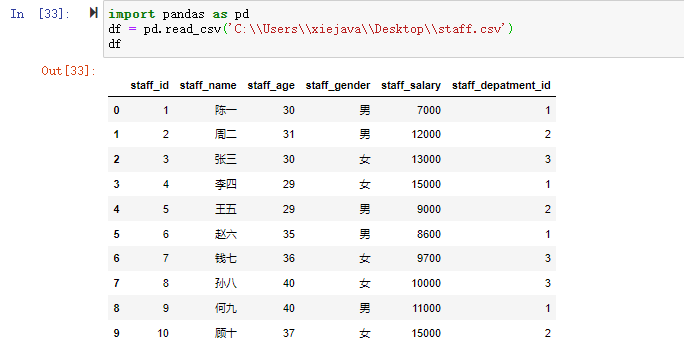
三、读取MySQL数据库表
在许多应用中,数据很少取自文本文件,因为这种方式存储数据量有限且比较低效。最常见的是基于SQL的关系型数据库如MySQL、MS-SQL、PostgreSQL等。pandas将关系型数据库加载到DataFrame的过程很简单,通过read_sql_query()方法就可以快速的将数据加载。
同样是staff的数据集,在mysql中的表结构如下:
1 | CREATE TABLE `staff` ( |
数据如下: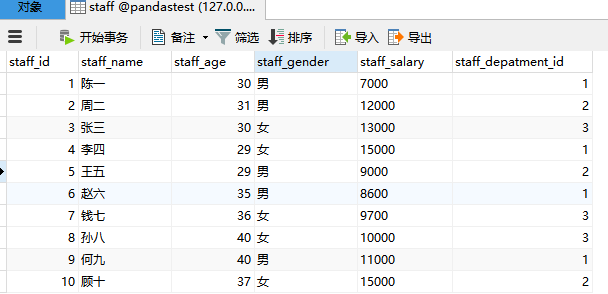
代码如下:
1 | import pandas as pd |
输出: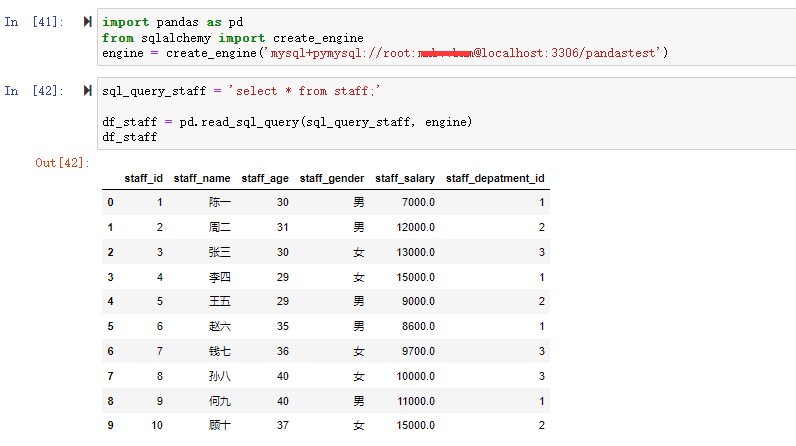
四、读取Web API的数据
除了本地文件和数据库外,许多网站和web应用都有一些通过JSON或其他格式提供数据的公共API。可以通过Python的requests包来访问这些API获得相应的数据,经过解析处理后加载到pandas的DataFrame中。
为了演示方便,本文通过Flask做了一个staff数据集的API,效果如下: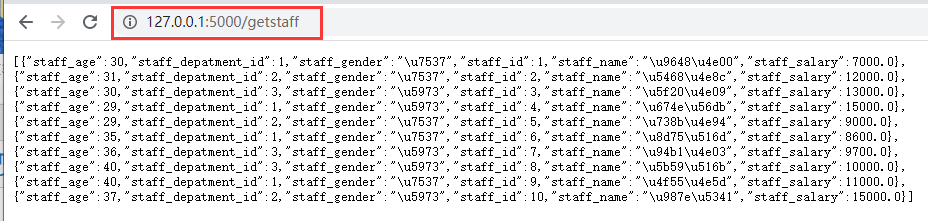
通过requests包来访问API,通过json包来解析json,然后加载到pandas的DataFrame中。
代码如下:
1 | import requests |
输出: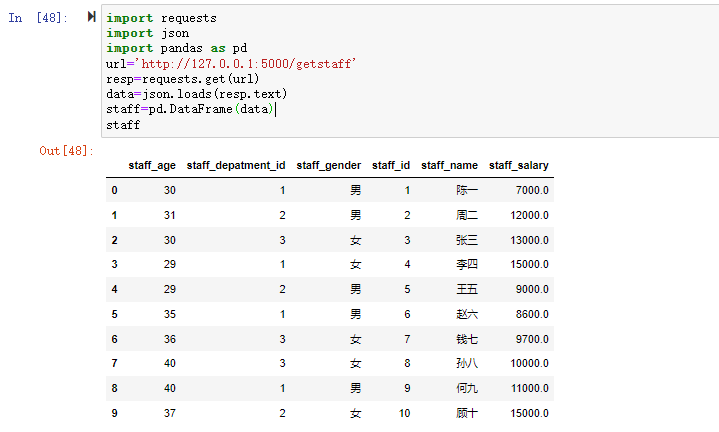
至此,通过staff测试数据集介绍了pandas的常用多种类型数据源的加载,包括csv、excel、mysql、web API。可以看出pandas对于数据加载非常的方便高效。
全部数据集及源代码:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!