我们在数据处理的过程中经常碰到需要对数据进行转换的工作,比如将原来数据里的字典值根据字典转义成有意义的说明,将某些数据转换成其他的数据,将空值转换成其他值,将数据字段名进行重命名等。pandas作为数据处理分析的利器当然为上述的这些数据转换提供了便捷的方法。我们可以利用pandas提供的映射、替换、重命名等操作方便的进行相应的数据转换操作。
本文通过实例重点介绍pandas常用的数据转换工具映射map()、替换replace()、重命名rename()
映射:map()函数 对数据集Serice中的元素根据映射关系进行映射(作用于Serice或DataFrame对象的一列)
替换:replace()函数 替换元素 (作用于DataFrame)
重命名:rename()函数 替换索引 (作用于index或columns)
一、映射 map()
在平时数据处理的过程中常常会碰到,某个字段(数据列)是数字表示的要根据映射表转换成有意思的字符。如性别在数据集里存的是1和2分别表示“男”和“女”,如何将数据集中“性别”列的1和2替换成“男”和“女”如何做?绝对不能用for循环一个个去替换。pandas也好、Numpy也好,都是针对数据集处理的,我们应该抛弃以前针对单个数据处理的思维去拥抱针对数据集来编程。使用pandas的map()方法,最少仅需一行代码就可以解决。
map() 函数是做用于 Series 或 DataFrame 对象的一列,它接收一个函数或表示映射关系的字典做为参数,它的基本语法格式以下:
1 | Series.map(arg,na_action=None) |
函数中的参数说明以下:
- arg:接收 function、dict 或 Series,表示映射关系;
- na_action:类似R中的na.action,取值为None或ingore,用于控制遇到缺失值的处理方式,设置为ingore时串行运算过程中将忽略Nan值原样返回。
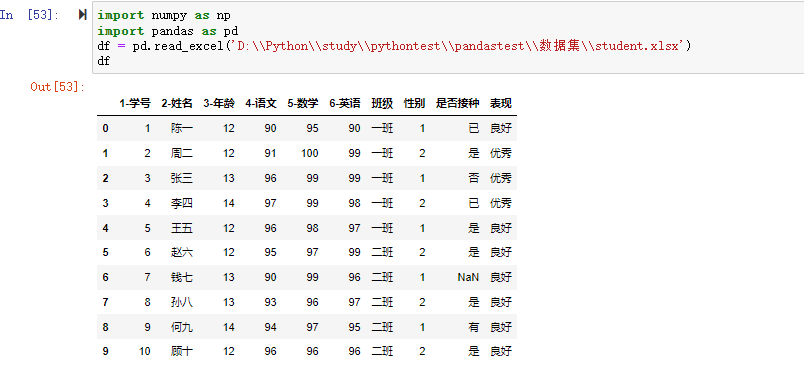
下面通过实例来说明pandas的map()的使用,演示的student数据集如下:
1 | import numpy as np |
1、通过数据字典映射
map()方法接受数据字典参数,通过数据字典将数据进行映射。如我们需要将“性别”列的1和2替换成“男”和“女”,定义一个数据字典{1:’男’,2:’女’},将1映射成“男”,将2映射成“女”。
1 | gender_map={1:'男',2:'女'} |
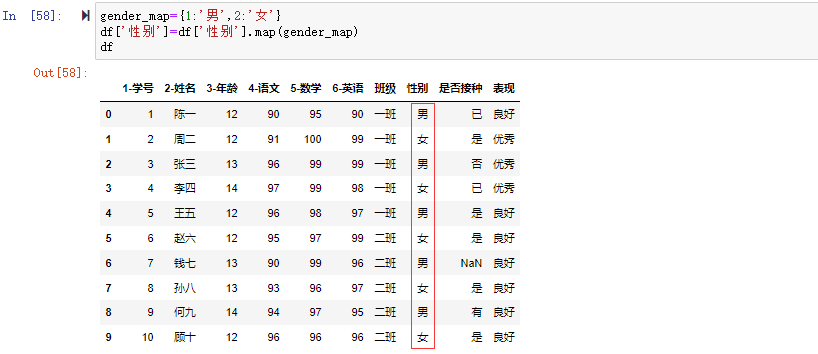
可以看到通过map()将需要转换的列的值进行的转换,具体的转换过程如下图所示:
2、lambda函数映射
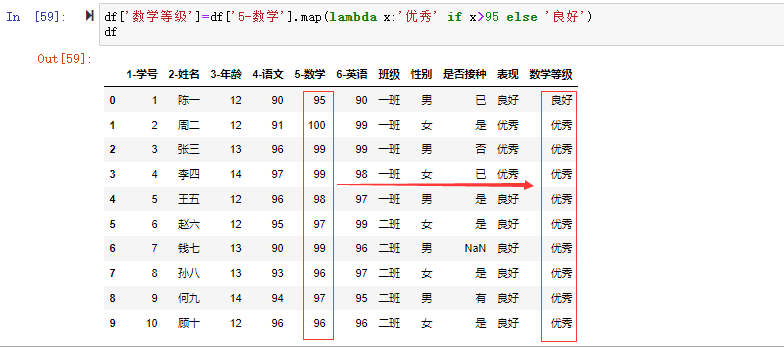
map()方法还接受lambda函数的方式进行值的映射,如我们现在要把数学分数为95分以上的映射数学等级为“优秀”,95及以下的映射为“良好”。可以通过lambda函数进行映射。
1 | df['数学等级']=df['5-数学'].map(lambda x:'优秀' if x>95 else '良好') |
3、通用函数映射
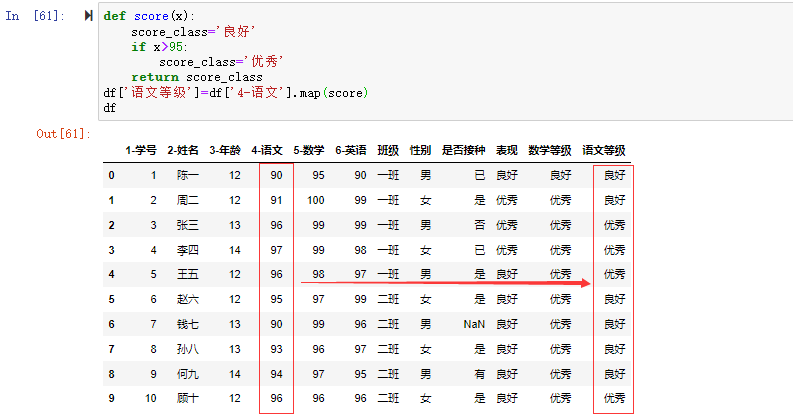
map()方法可以接收自定义通用的函数进行值的映射,如我们现在要把语文分数为95以上的映射为语文等级为“优秀”,95及以下的映射为“良好”,也可以通过自定义函数来实现映射。
先定义一个函数score(x)用于接收需要映射的值。
1 | def score(x): |
二、替换 replace()
如果要对全DataFrame数据集中的数据进行某种替换,map()可能需要对数据集中的每个列都进行map()操作才可以,但是通过pandas的替换方法replace可以一次性替换掉DataFrame中所有的数据。如:我们现在要将数据集中所有的“良好”替换成“良”,所有的“优秀”替换成“优”
可以直接通过 df.replace(['优秀','良好'],['优','良']) 一句代码搞定。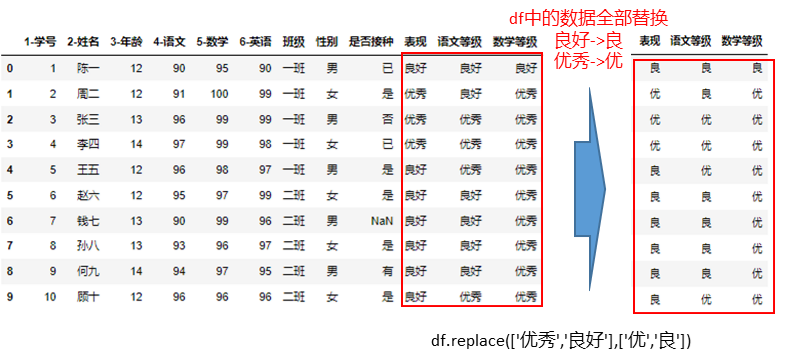
以前文章中介绍了处理缺失值用fillna的方式来填充缺失值,用replace则提供了一种更加简单、灵活的处理缺失值或异常值的方式。
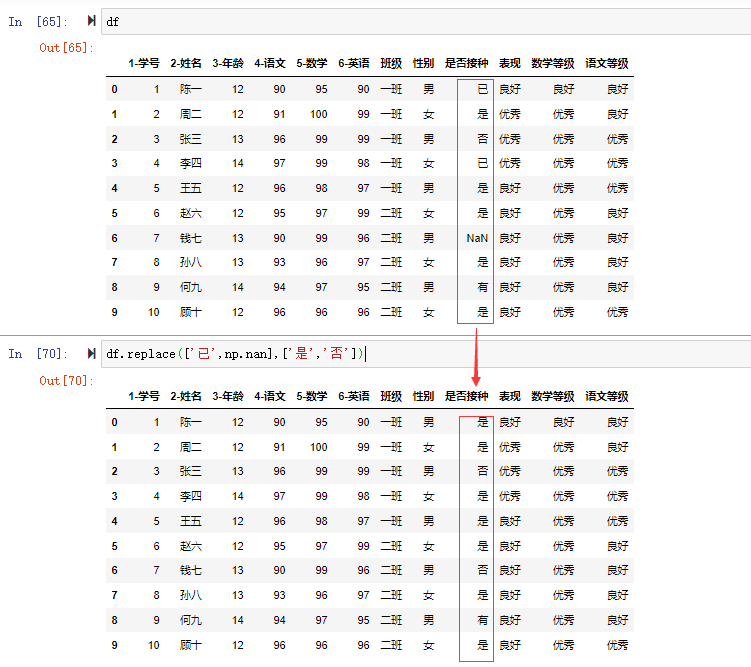
如在数据集中有一个数据列“是否接种”,这里的值有“已”、“是”、“否”、NaN,实际是在收集统计表格的时候大家填的数据不一致,不标准。现在需要将“已”的全部改成“是”,NaN没有填的改成“否”
1 | df.replace(['已',np.nan],['是','否']) |
三、重命名 rename()
在数据处理的过程有时候需要对列索引进行重命名,一个典型的例子就是对于数据的检索或其他操作df[column]对于任意列名均有效,但是df.column只在列名是有效的Python变量名时才有效。
我们在检索英语大于95分的数据时可以用df[df['6-英语']>95]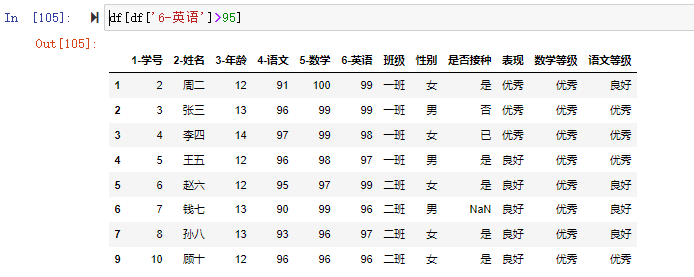
但是用df.query('6-英语 >95') 就会报列名没有定义的错,因为’6-英语’列名不是有效的Python变量名。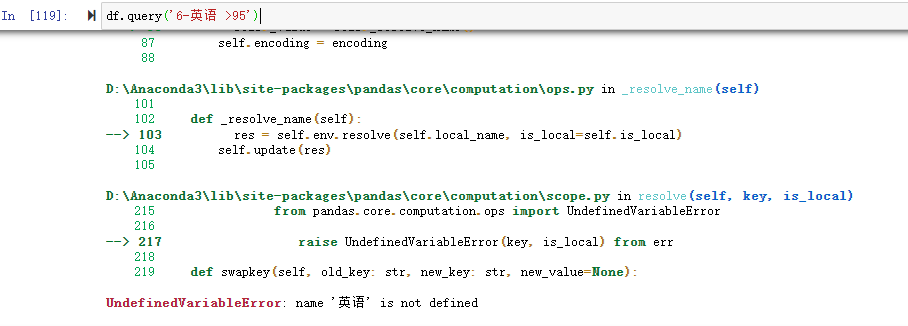
这时候就需要将列名重命名为有效的Python变量名,有效的Python变量名应该是只能_,数字,字母组成,不可以是空格或者特殊字符(!@#$%^&*~),不能是数字开头,不能有中文。我们将“6-英语”的列名重命名为“english”。注意带上inplace=True参数用于更新作用于本数据集,而不是返回一个新的数据集。
1 | df.rename(columns={'6-英语':'english'},inplace=True) |
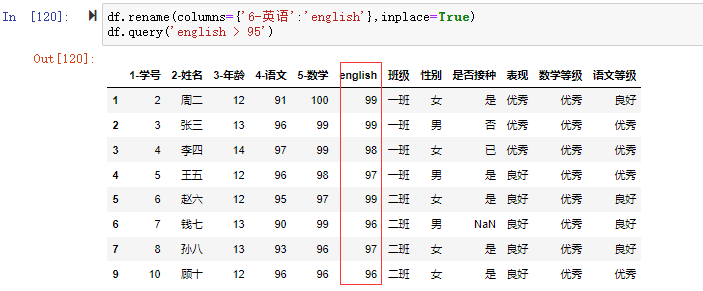
可以看到“6-英语”列名改成了“english”,并且df.query(‘english > 95’)不报错,可以正常检索出数据了。
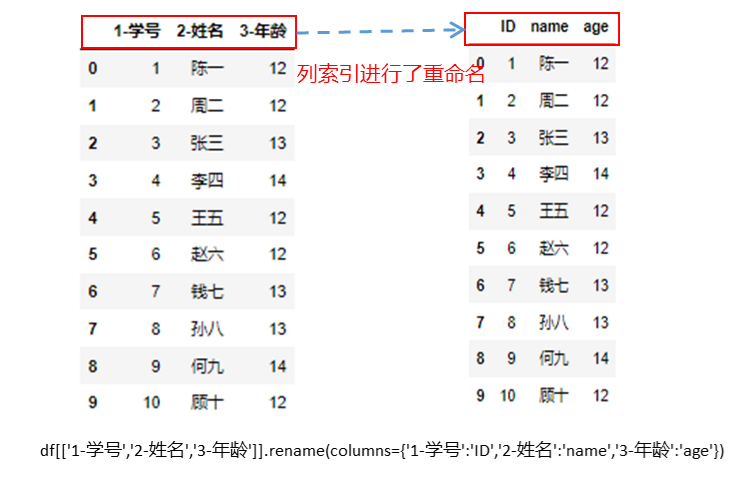
更多的,如果要重命名多个列,可以传入一个需要重命名的多个字典值,进行多个列的重命名。
1 | df[['1-学号','2-姓名','3-年龄']].rename(columns={'1-学号':'ID','2-姓名':'name','3-年龄':'age'}) |
如果需要重命名行索引,可以通过df.rename(index={‘原索引’:’重命名索引’})的方式进行重命名。
至此,本文通过几个实例介绍了pandas常用的数据转换工具映射map()、替换replace()、重命名rename()
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!