![]()
Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。是学习数据分析、AI机器学习必学组件之一。
Pandas 这个名字来源于面板数据(Panel Data)与数据分析(data analysis)这两个名词的组合。在经济学中,Panel Data 是一个关于多维数据集的术语。Pandas 对数据的处理是为数据的分析服务的,它所提供的各种数据处理方法、工具是基于数理统计学出发,包含了日常应用中的众多数据分析方法。
Pandas 可以实现复杂的处理逻辑,这些往往是 Excel 等工具无法处理的,还可以自动化、批量化,对于相同的大量的数据处理我们不需要重复去工作。Pandas 的出现使得 Python 做数据分析的能力得到了大幅度提升,它主要实现了数据分析的五个重要环节:
- 加载数据
- 整理数据
- 操作数据
- 构建数据模型
- 分析数据
主要特点
- 它提供了一个简单、高效、带有默认标签(也可以自定义标签)的 DataFrame 对象。
- 能够快速得从不同格式的文件中加载数据(比如
Excel、CSV 、SQL文件),然后将其转换为可处理的对象; - 能够按数据的行、列标签进行分组,并对分组后的对象执行聚合和转换操作;
- 能够很方便地实现数据归一化操作和缺失值处理;
- 能够很方便地对 DataFrame 的数据列进行增加、修改或者删除的操作;
- 能够处理不同格式的数据集,比如矩阵数据、异构数据表、时间序列等;
- 提供了多种处理数据集的方式,比如构建子集、切片、过滤、分组以及重新排序等。
本教程梳理了快速入门pandas的一些知识点。
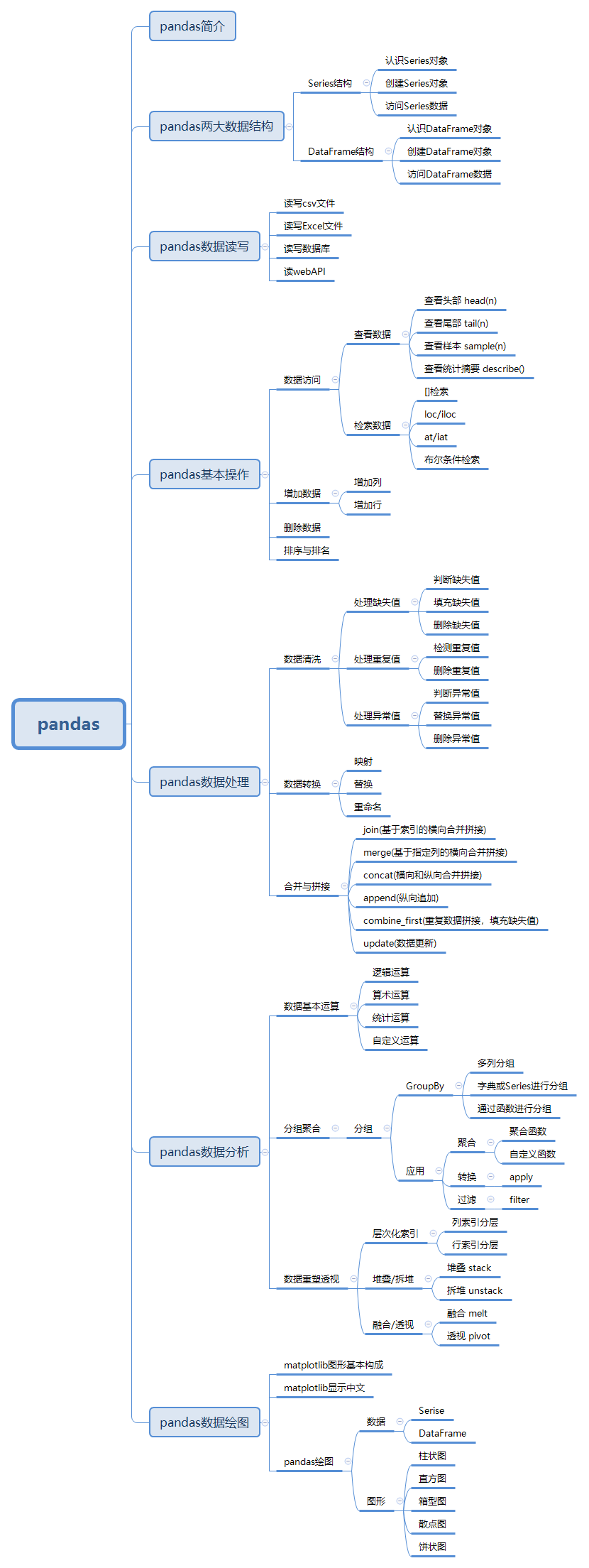
一、pandas数据结构(Series和DataFrame)
二、pandas数据加载(csv、excel、json、mysql、webAPI)
六、pandas数据处理之数据转换(映射map、替换replace、重命名rename)
七、pandas数据分析之数据运算(逻辑运算、算术运算、统计运算、自定义运算)
十、pandas数据分析之数据重塑透视(stack、unstack、melt、pivot)
学习pandas最好的资料肯定是pandas的官网 https://pandas.pydata.org/docs/user_guide/index.html
书籍推荐pandas的作者写的《利用python进行数据分析》
本教程作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!