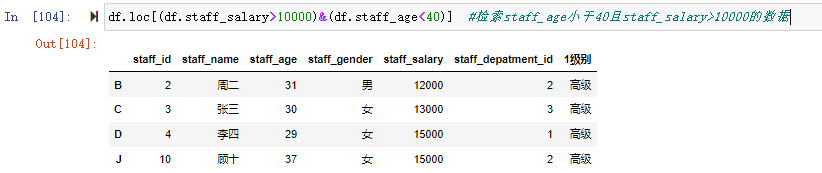
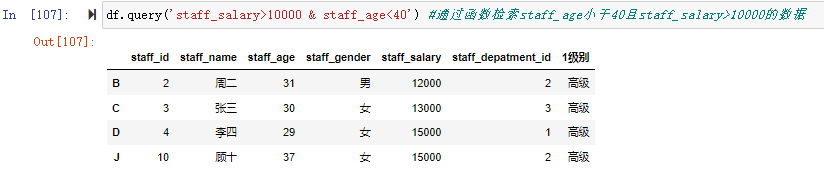
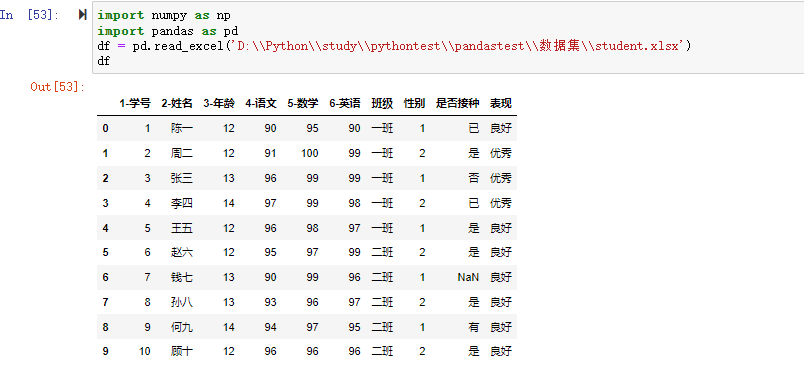
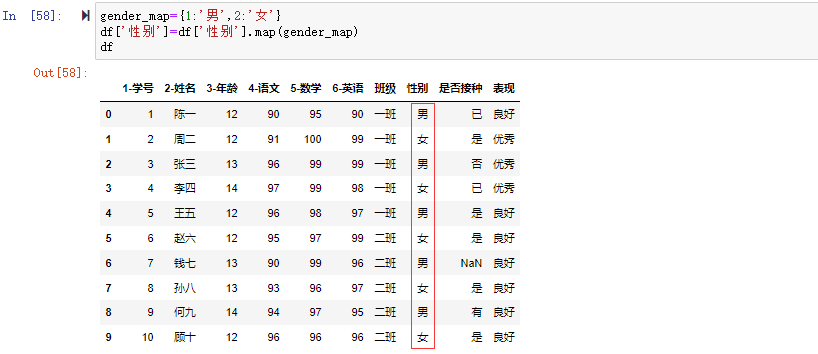
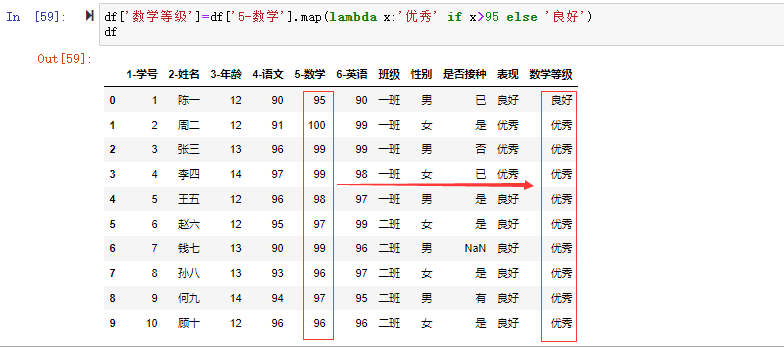
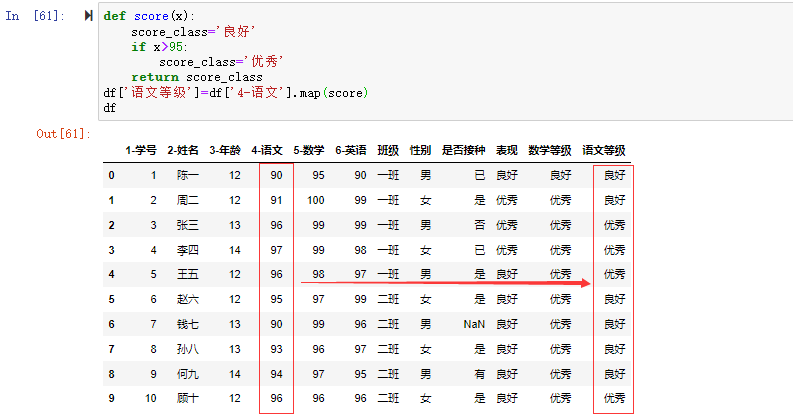
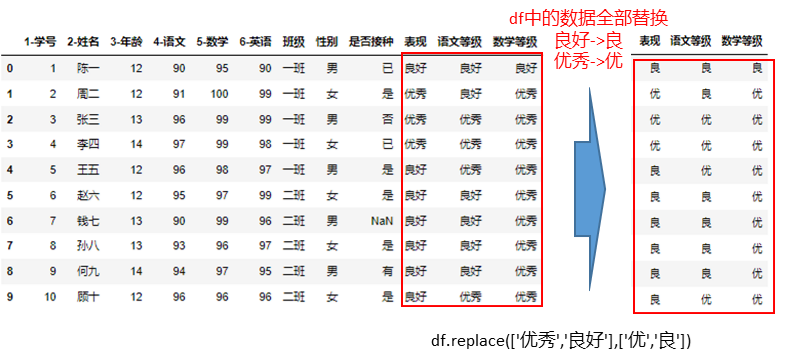
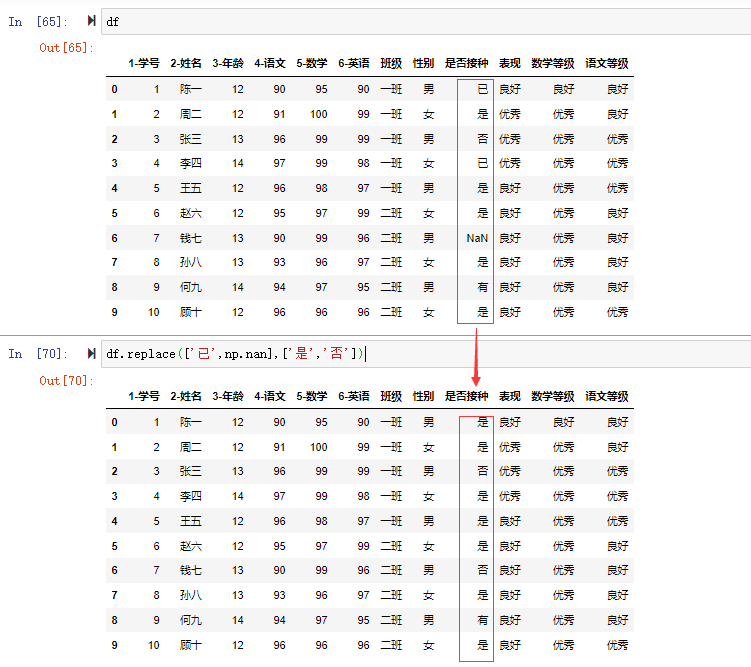
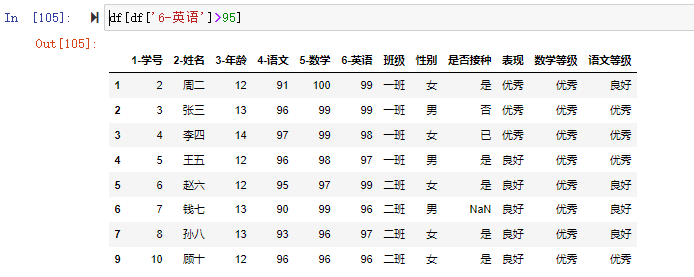
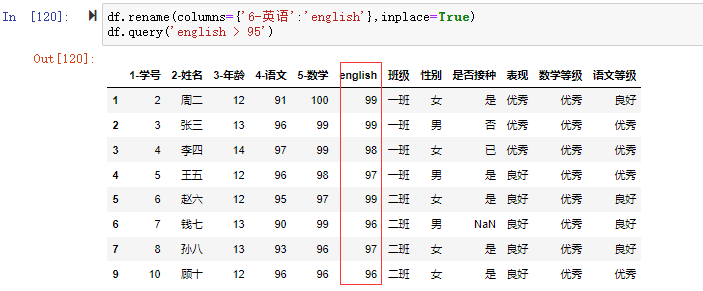
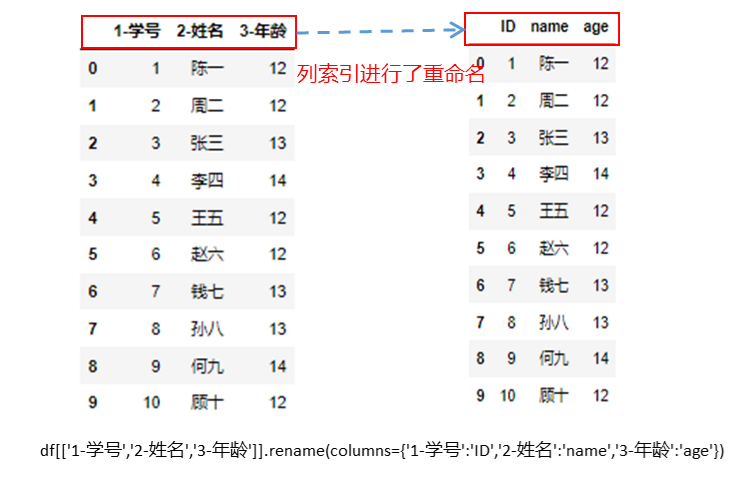
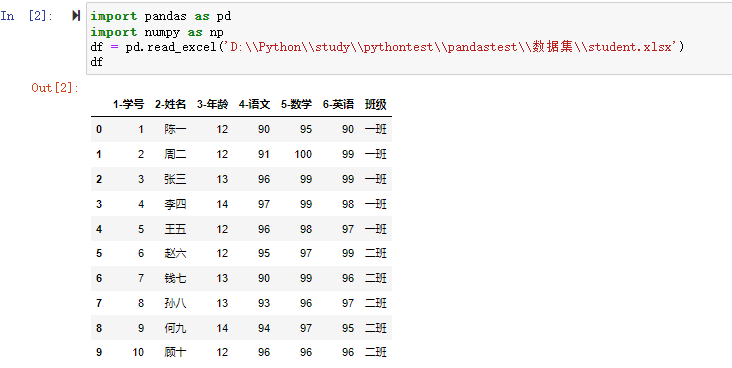
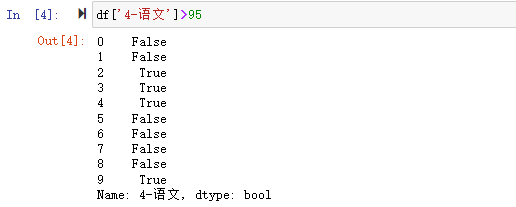
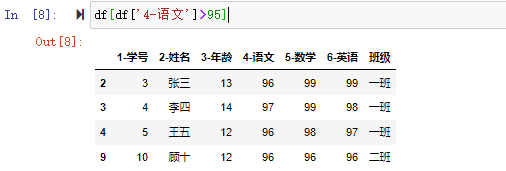
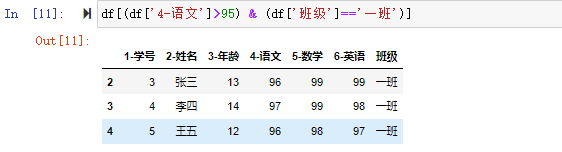
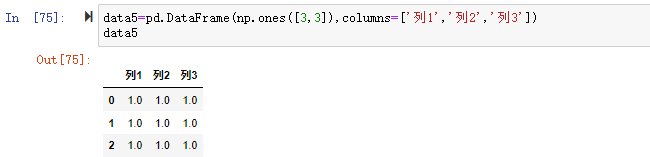
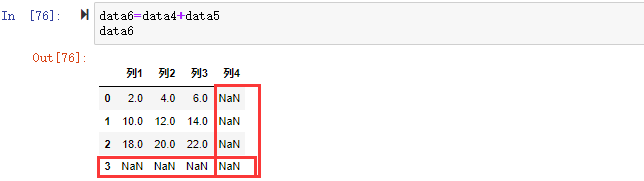
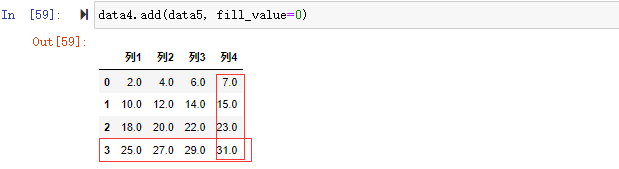
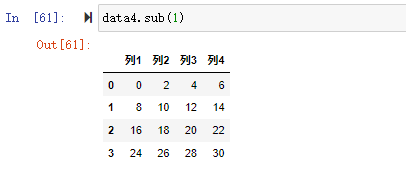
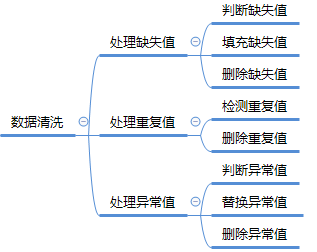
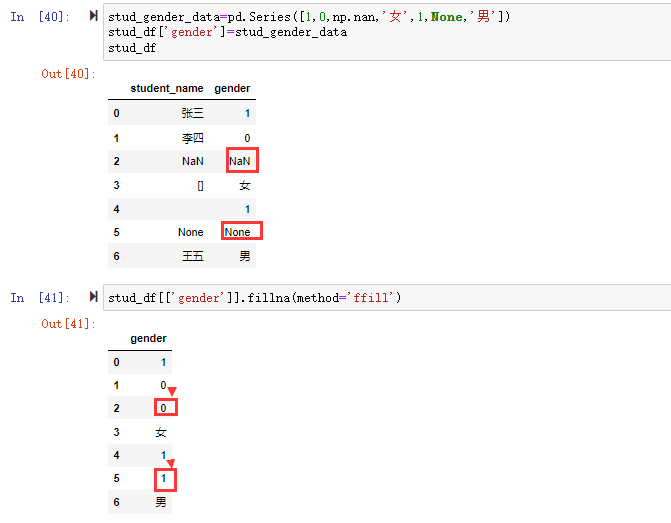
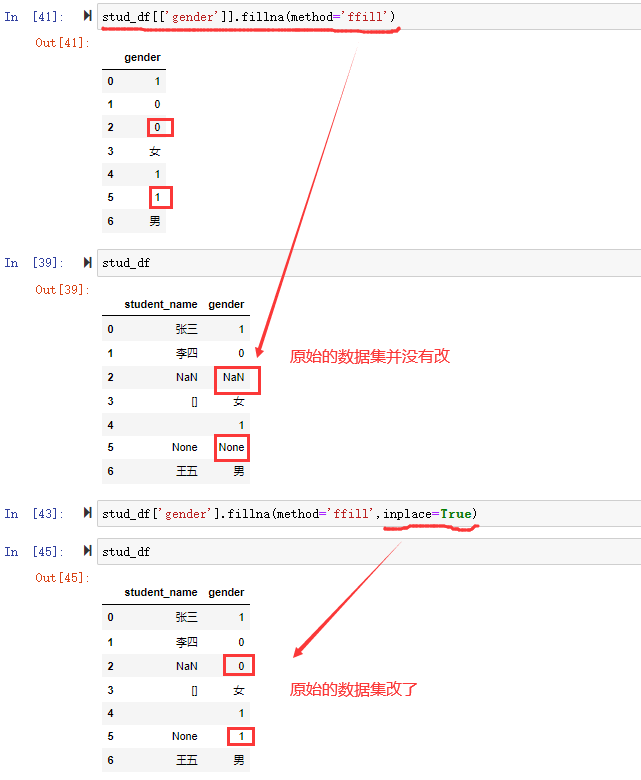
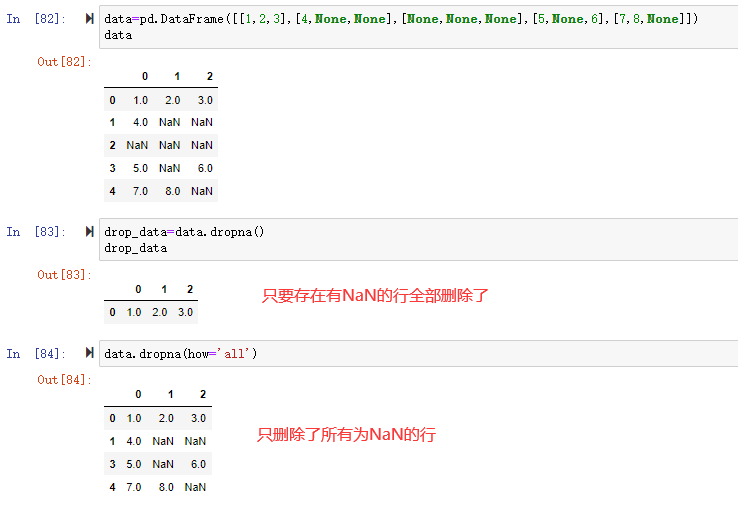
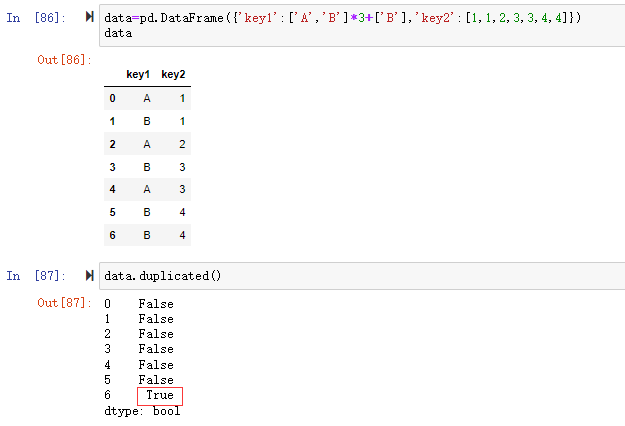
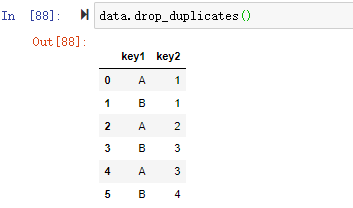
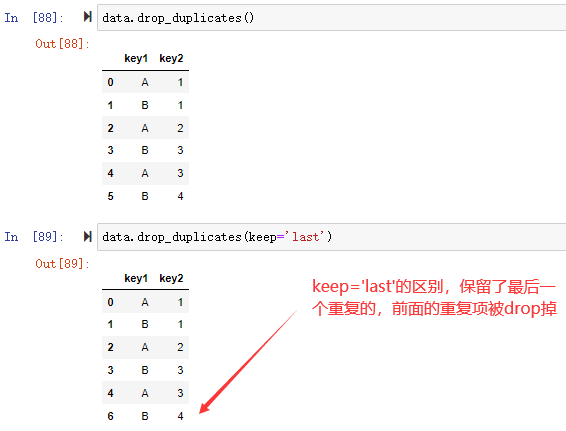
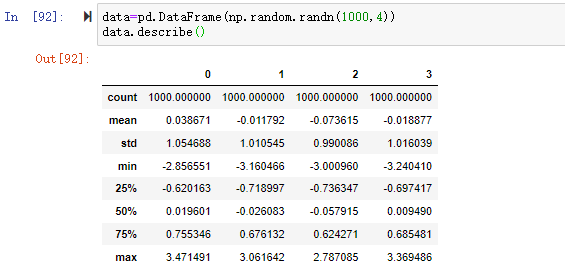
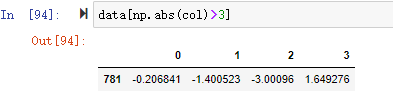
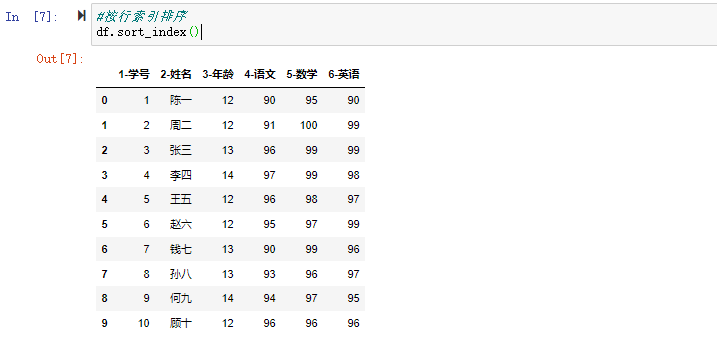
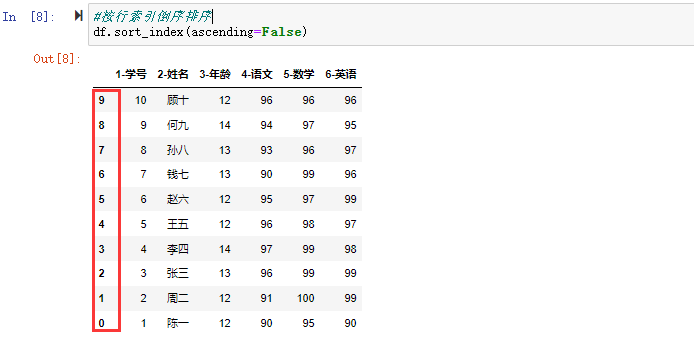
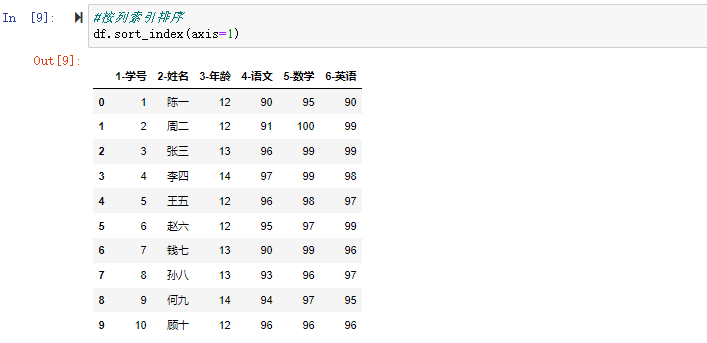
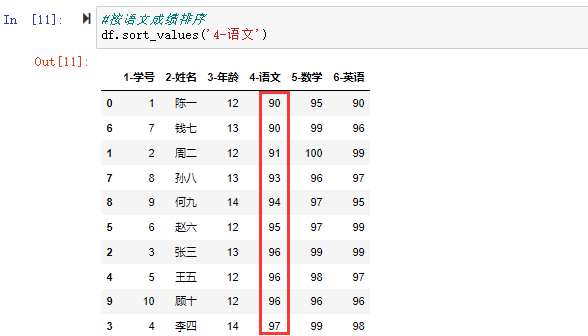
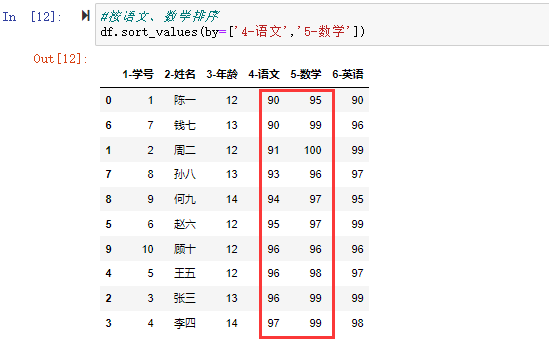
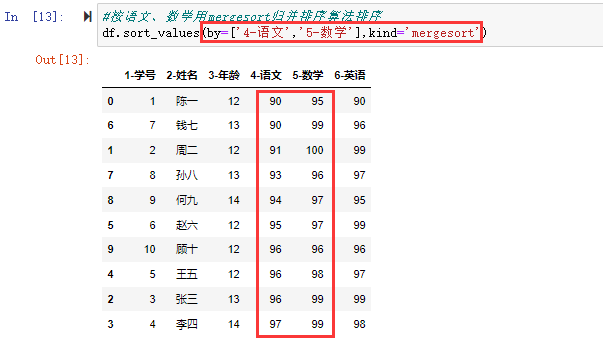
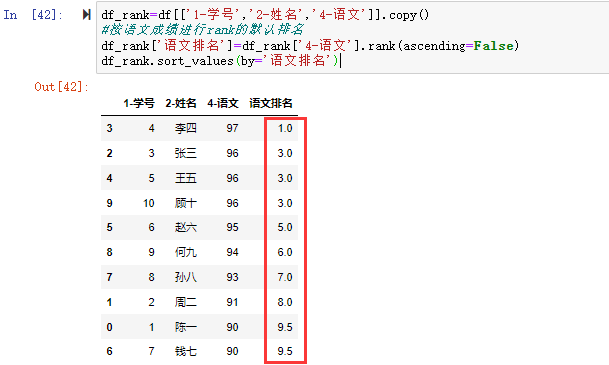
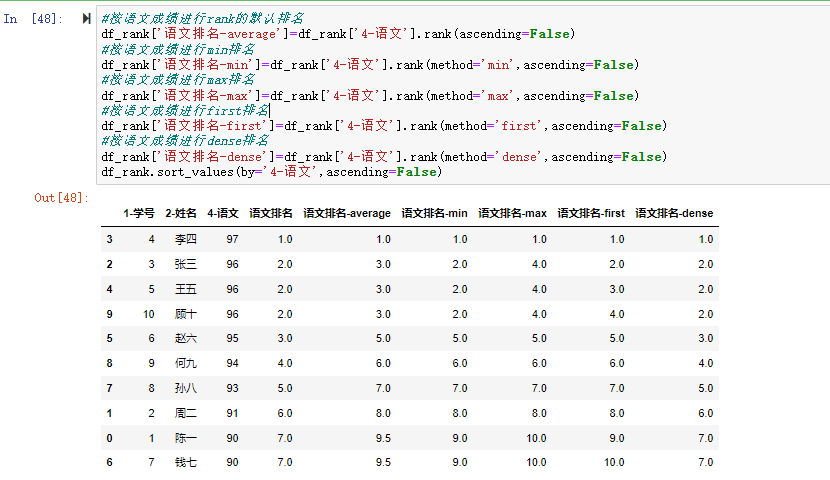
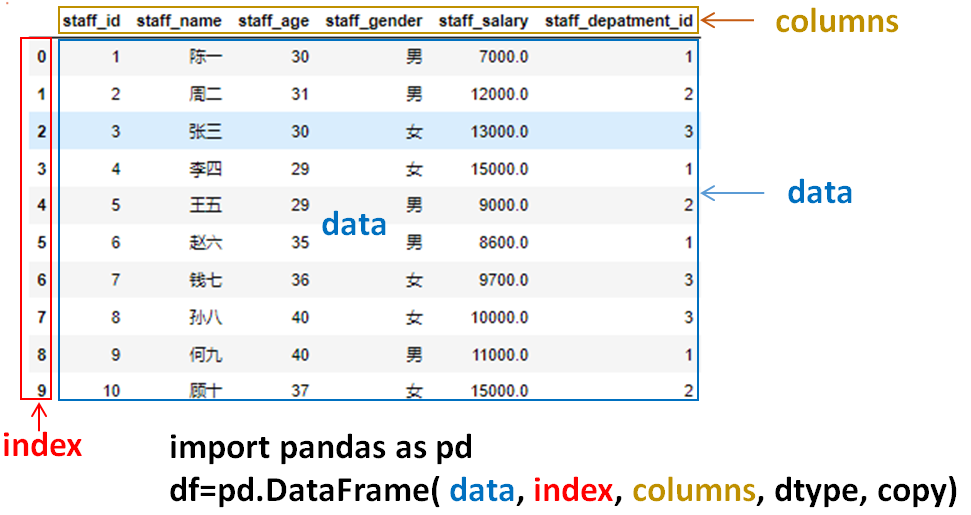
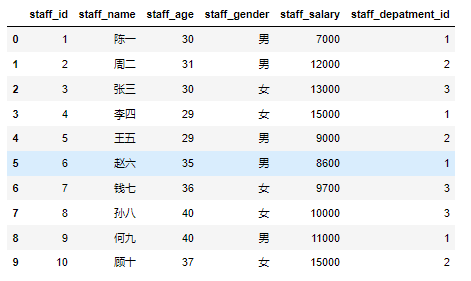
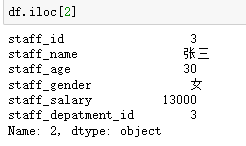
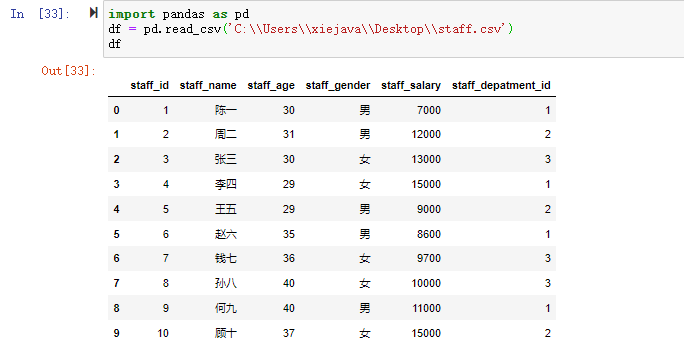
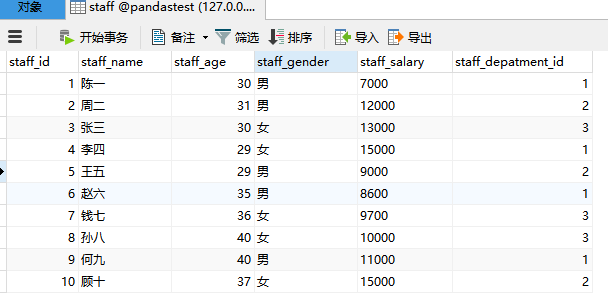
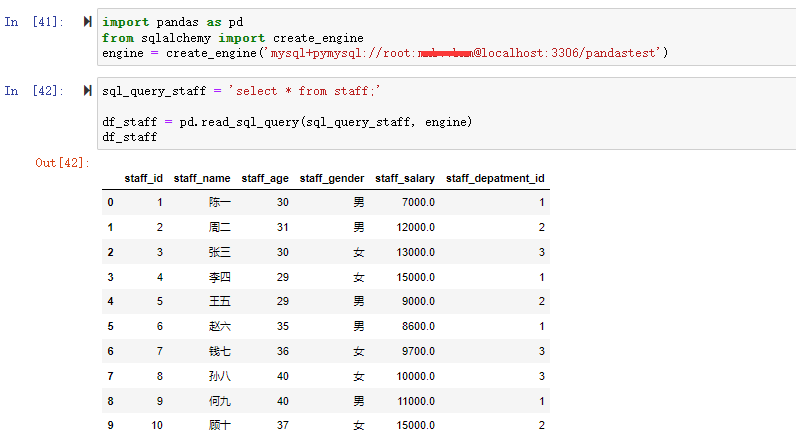
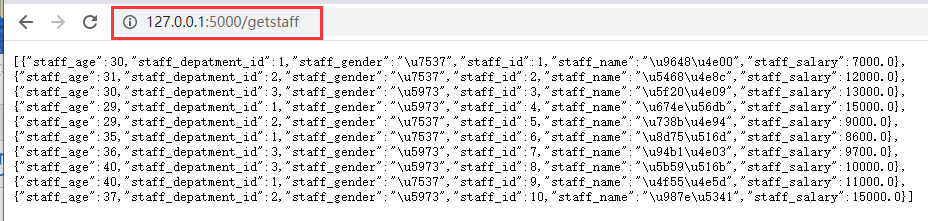
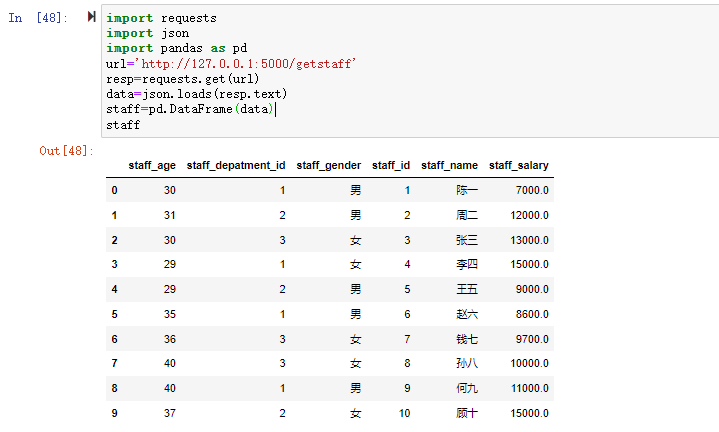
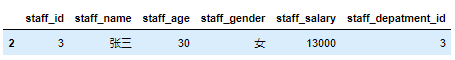在数据分析过程中,经常会需要根据某一列或多列把数据划分为不同的组别,然后再对其进行数据分析。本文将介绍pandas的数据分组及分组后的应用如对数据进行聚合、转换和过滤。
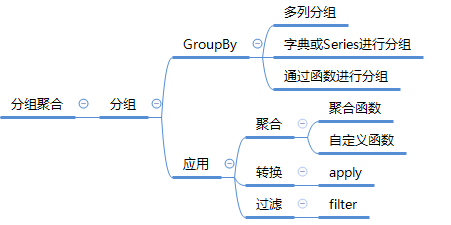
在关系型数据库中我们常用SQL的GROUP BY操作进行分组分析计算。在pandas中要完成数据的分组操作同样可用groupby()函数,然后再在划分出来的组(group)上应用一些统计函数,从而达到数据分析的目的,比如对分组数据进行聚合、转换或者过滤。这个过程主要包含以下三步:拆分(split)-应用(apply)-合并(combine)
例如,DataFrame可以在列(axis=1)或行(axis=0)上进行分组(split),然后将一个函数应用(apply)到各个分组并产生一个新值,最后所有这些函数的执行结果会被合并(combine)到最终的结果对象中。
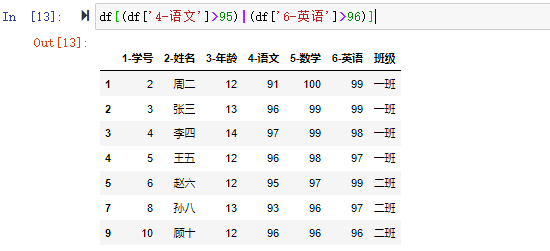
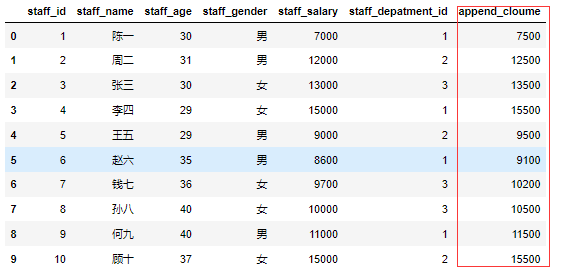
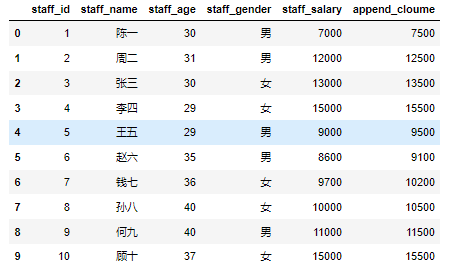
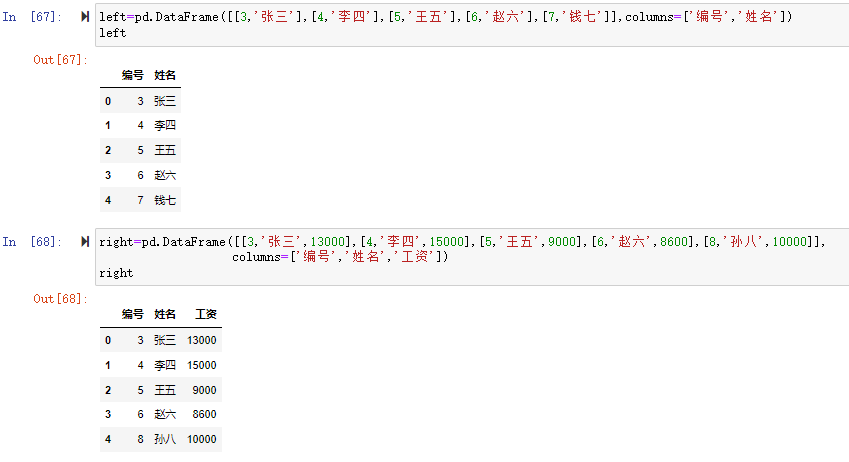
一个简单的分组聚合的过程如下图所示: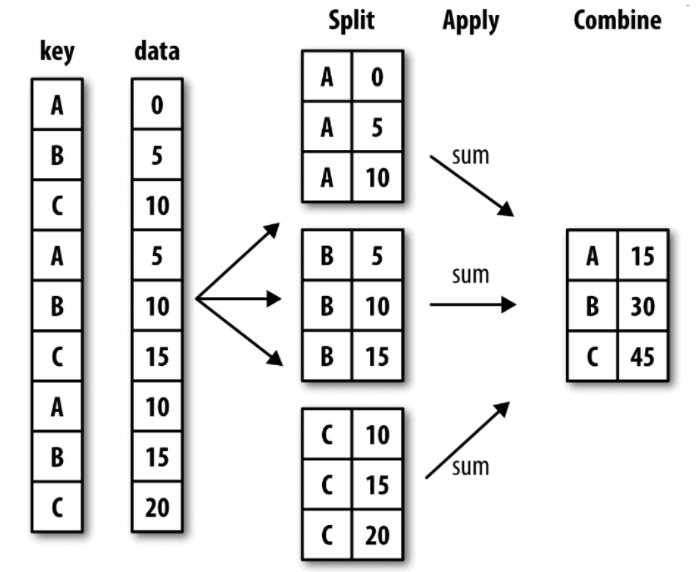
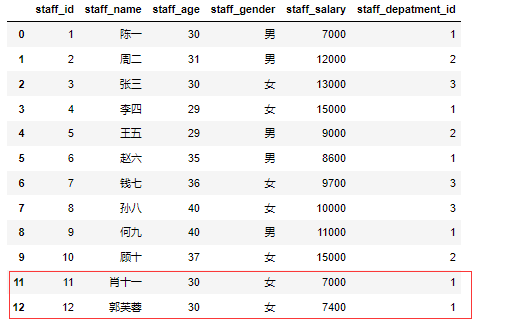
我们来构造图中所示的DataFrame数据集,看看pandas的分组聚合是怎么做的。
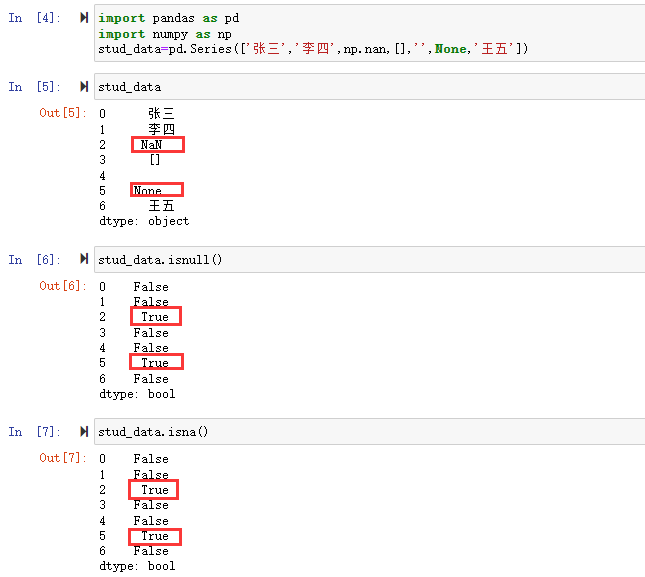
1 | import pandas as pd |
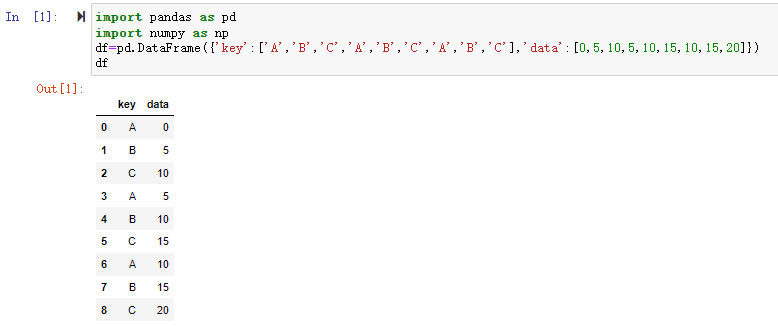
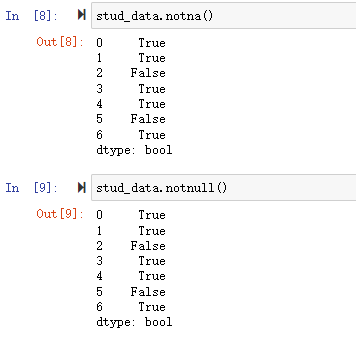
1 | grouped=df.groupby(['key']) #通过key分组 |
通过对df的key进行用groupby()进行分组,这里可看到,将数据分成了A、B、C三组,然后对这三组分别应用sum()函数求和,再组合成最终的结果。
对于分组聚合一般来说实际上是分两步:一是创建分组对象进行分组,二是对分组进行相应处理如(对组应用聚合函数、对组进行转换、对组的数据进行过滤)。不过实际在具体写的时候可以通过链式调用一个语句就可以实现如:
1 | df.groupby(['key']).sum() #链式调用先分组再用聚合函数聚合 |

一、创建分组对象进行分组
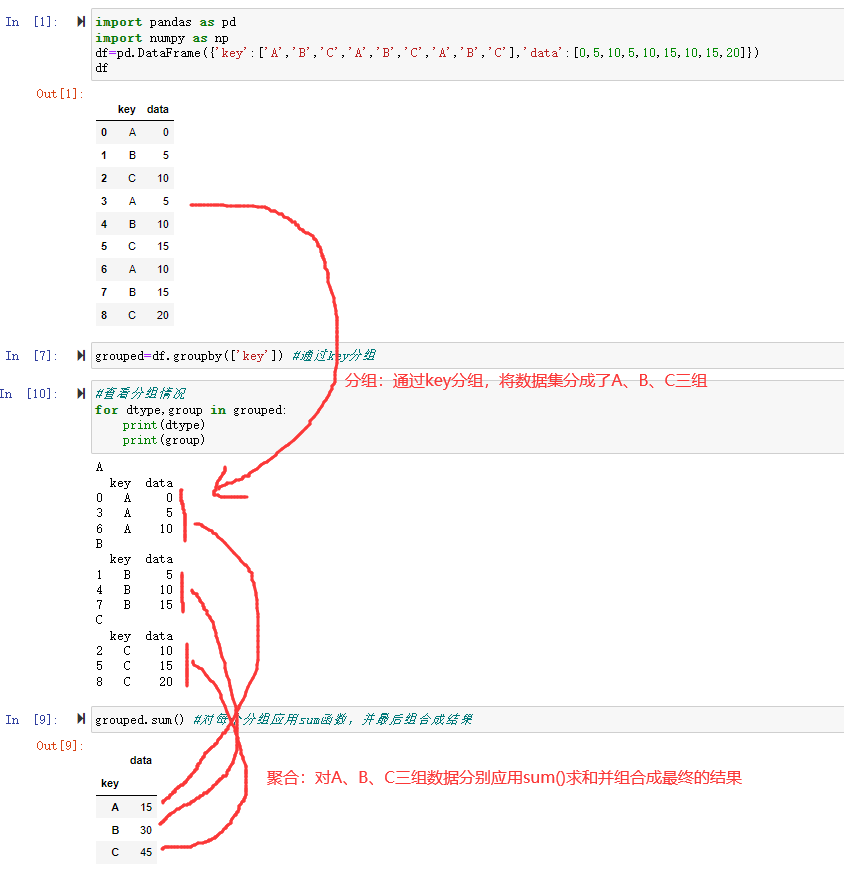
groupby可以把分组时指定的键(key)作为每组的组名。groupby对象支持迭代,可以遍历每个分组的具体数据。
如:
1 | #查看分组情况 |
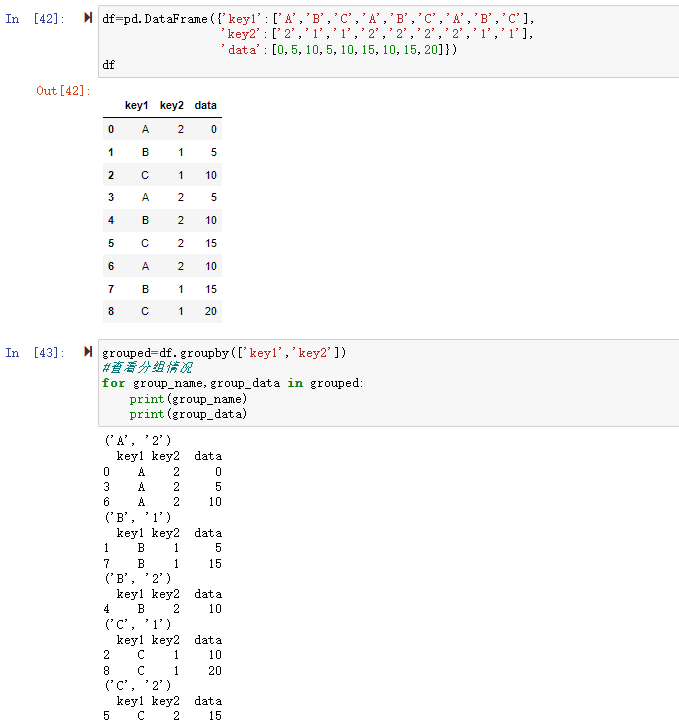
1、根据多列进行分组
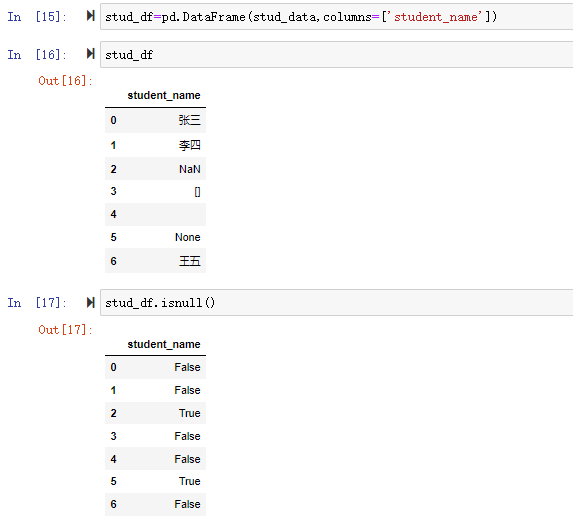
groupby可以通过传入需要分组的参数实现对数据的分组,参数可以是单列,也可以是多列,多列以列表的方式传入。
1 | grouped=df.groupby(['key1','key2']) |
2、通过字典或Series进行分组
除数组以外,分组信息还可以其他形式存在。如可以定义字典或Series进行分组。
1 | people=pd.DataFrame(np.random.randn(5,5), |
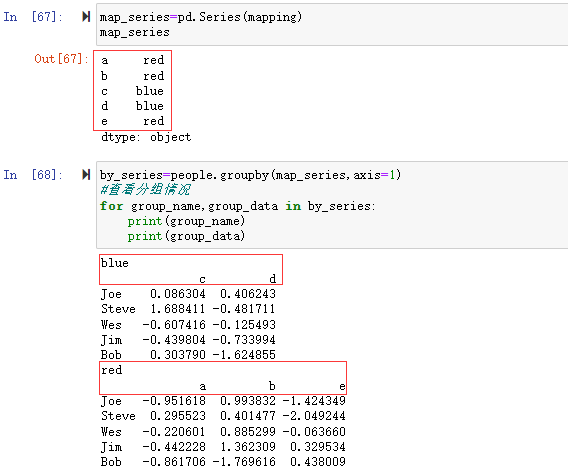
在字典中我们定义了mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red'}#定义分组字典
a、b、e对应“red”,c、d对应“blue”所以将blue和red分成了两组。%E8%81%9A%E5%90%88.png)
应用sum()求和函数,可以看到分别对blue和red的分组进行了求和。
类似的,Series也是一样的,我们将map转换成Series,可以看到分组结果和map分组一样的。
3、通过函数进行分组
比起使用字典或Series,使用Python函数是一种更原生的方法定义分组映射,。任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称。
如上面的people数据集,将姓名索引的长度进行分组。
1 | by_len=people.groupby(len) |
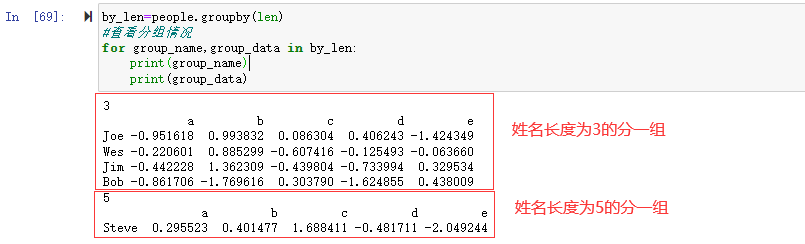
可以看到将姓名长度相同的3分成一组,长度为5的数据分成了一组
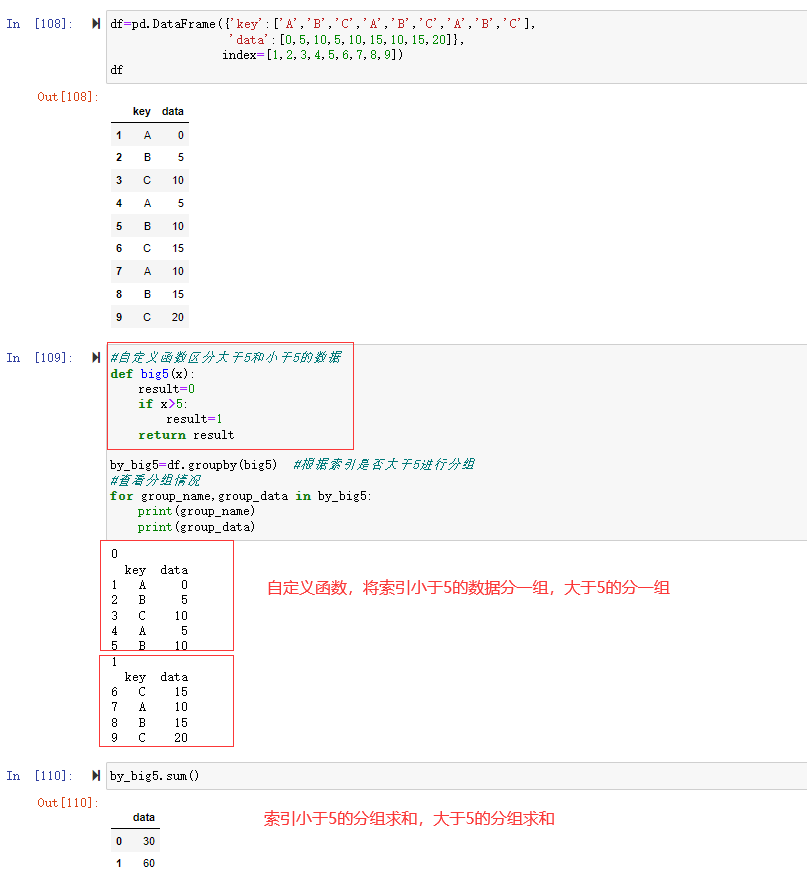
更加通用的是可以自定义函数进行分组,如要将索引>5的和小于5的分别分组,可以自定义函数
1 | #数据集 |
二、对分组后的数据进行应用
前面通过分组将数据集根据条件分组后,可以对分组后的数据进行各种处理包括聚合、转换、过滤等操作。
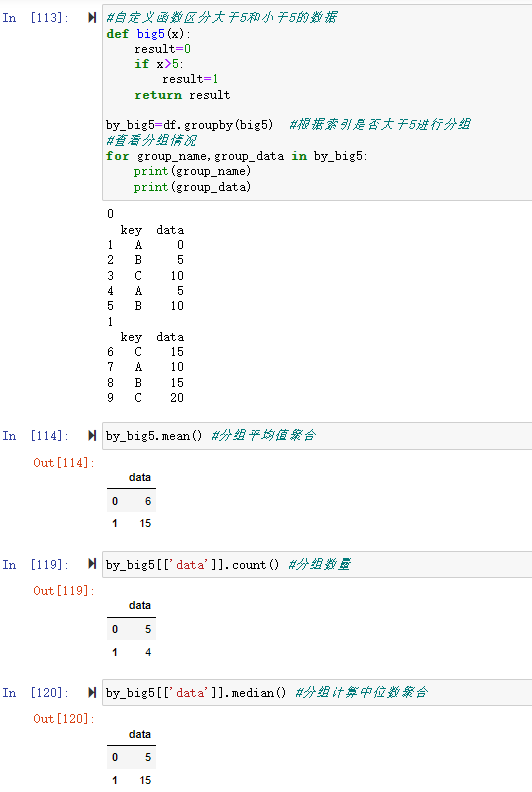
1、对分组数据用聚合函数进行聚合
a) 使用pandas聚合函数
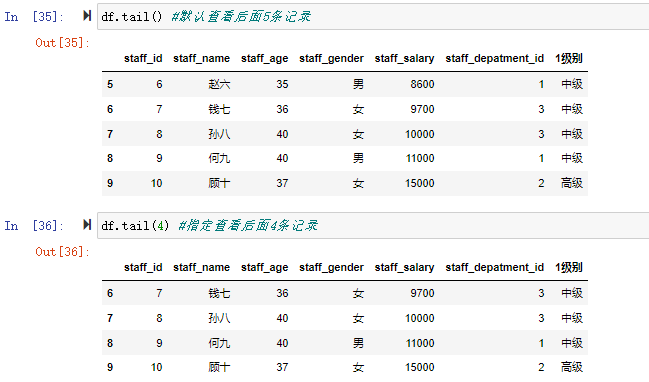
前面第一部分的例子中对数据分组后进行了sum()求和聚合操作,类似的聚合函数还有很多如:
| 函数名 | 描述 |
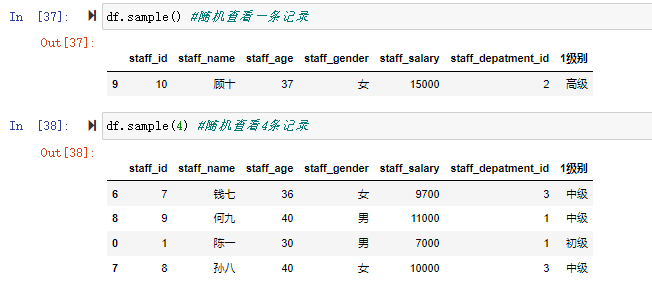
|---|---|
| count | 分组中非NA值的数量 |
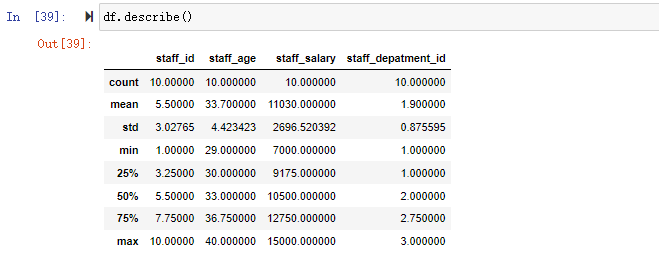
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的中位数 |
| std, var | 标准差和方差 |
| min, max | 非NA的最小值,最大值 |
| prod | 非NA值的乘积 |
| first, last | 非NA值的第一个,最后一个 |
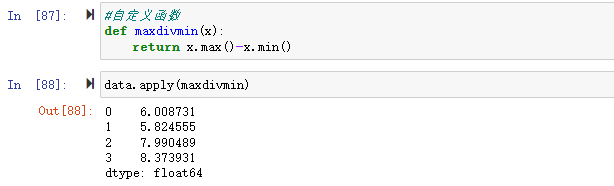
b) 使用自定义聚合函数
pandas的groupby分组对象还可以用自定义的聚合函数可以通过groupby分组对象,将你自己的聚合函数,传入aggregate或agg方法即可
1 | df=pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],'data':[0,5,10,5,10,15,10,15,20]}) |
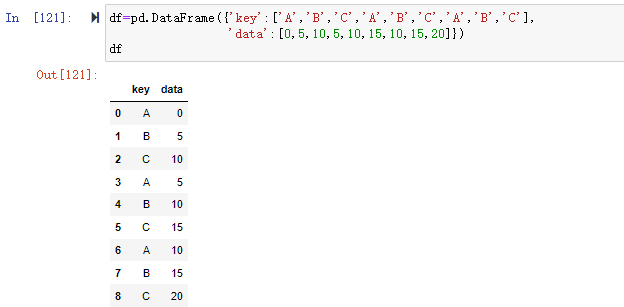
1 | grouped=df.groupby(['key']) |
1 | def peak_to_peak(arr): |
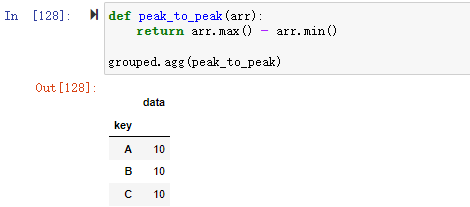
2、根据分组数据进行转换
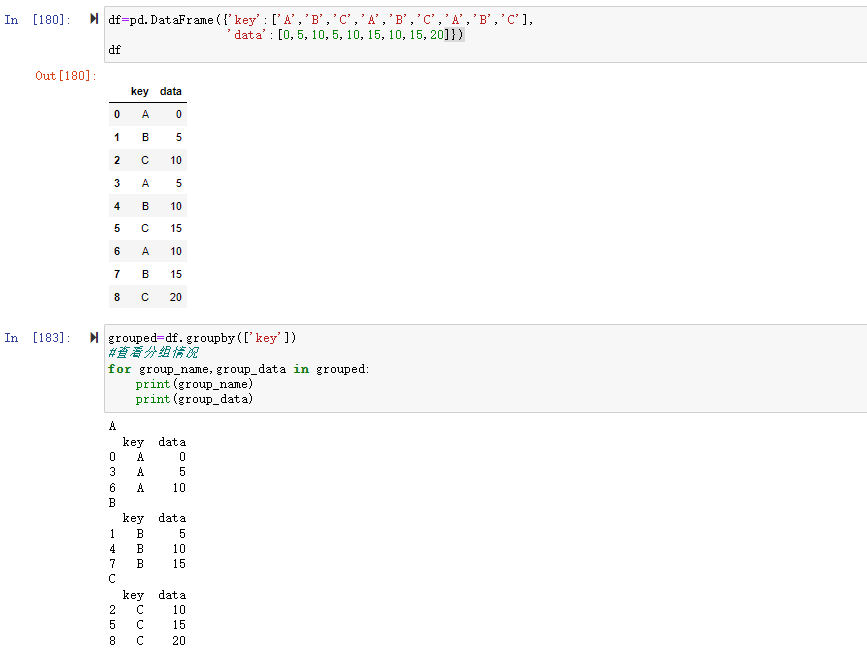
根据分组数据进行数据转换或其他操作,可以在分组的基础上用apply函数进行数据的转换。
如数据集
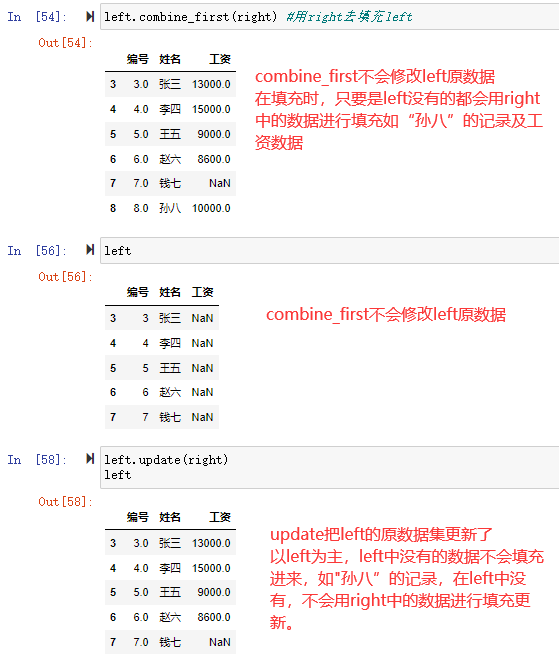
1 | df=pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'], |
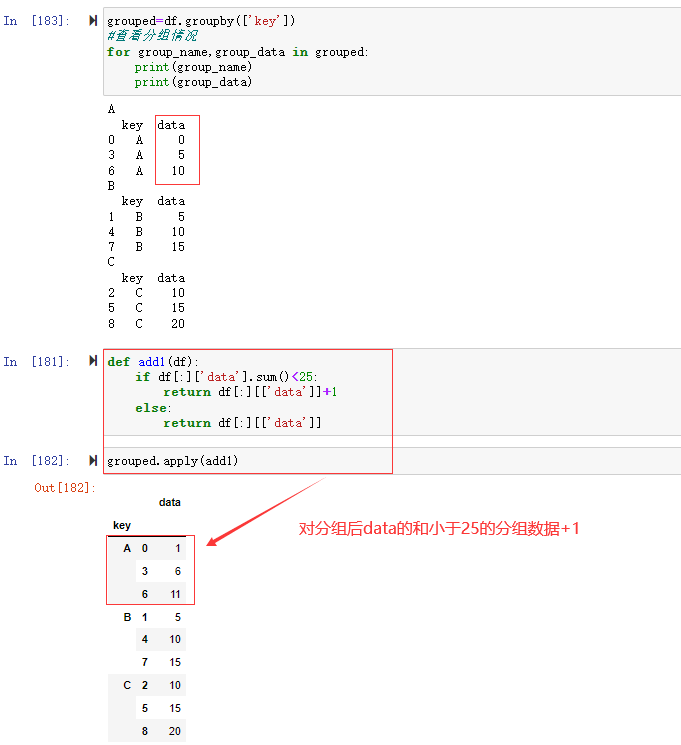
现在我们要对data求和后小于25的分组数据都加1
那么我们可以定义函数,然后再对分数数据进行应用
1 | def add1(df): |
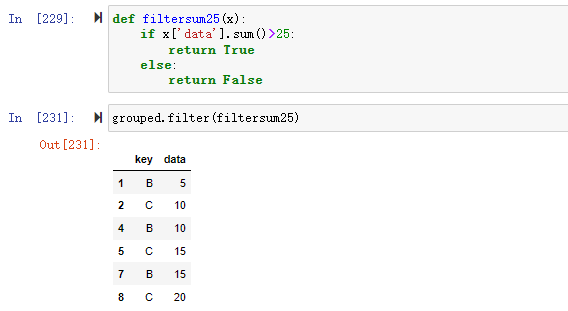
3、根据分组数据进行过滤
通过 filter() 函数可以实现数据的筛选,该函数根据定义的条件过滤数据并返回一个新的数据集。
如当我们要过滤掉分组后data求和小于25的数据
1 | #过滤掉sum()求和小于25的数据 |
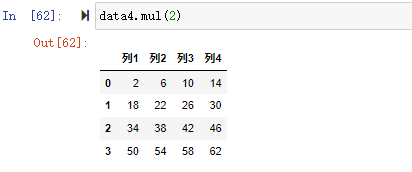
至此,本文通过实例介绍了pandas的数据分组及分组后的应用如对数据进行聚合、转换和过滤。数据的分组和聚合是数据分析中常用的分析手段,转换和过滤是数据处理中可用到的方法。
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!

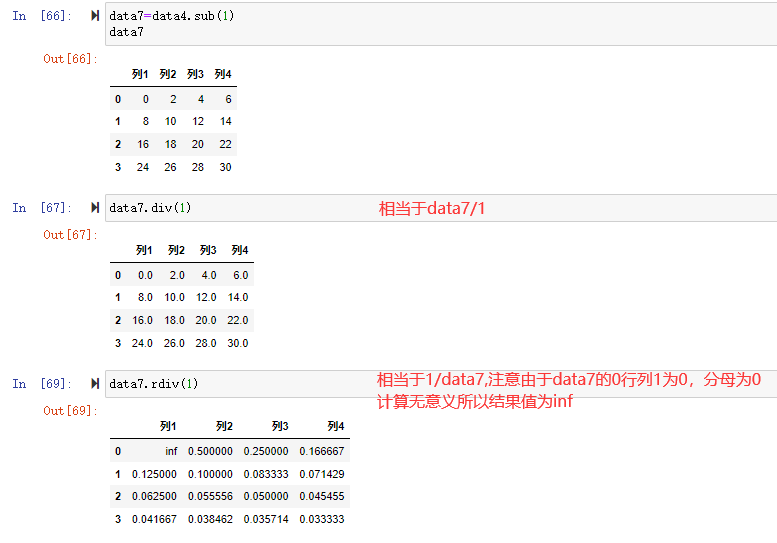
.png)
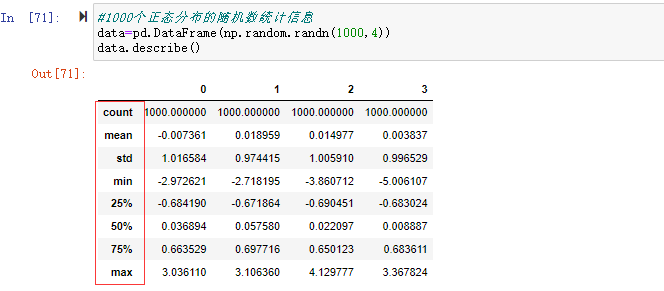
.png)
.png)
.png)
.png)
.png)




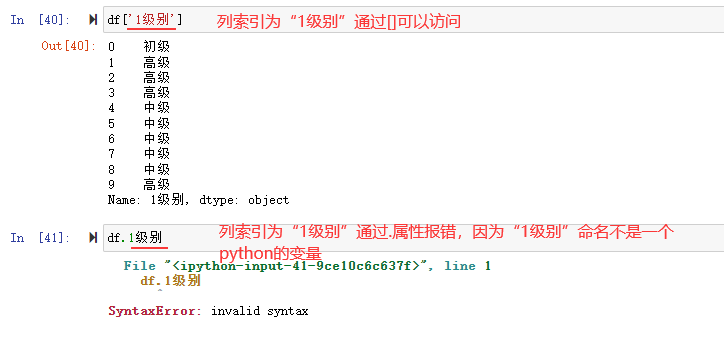
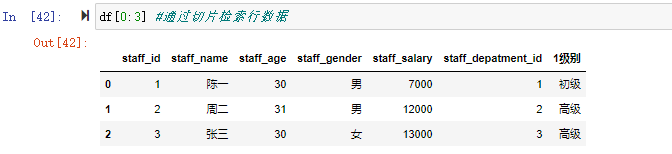
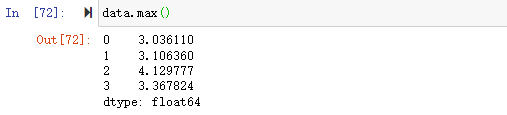
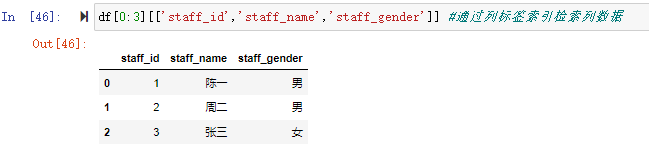
![df[0:3][1:2]](https://xiejava1018.github.io/xiejavaimagesrc/images/2022/20220207/%E5%88%87%E7%89%872.png)
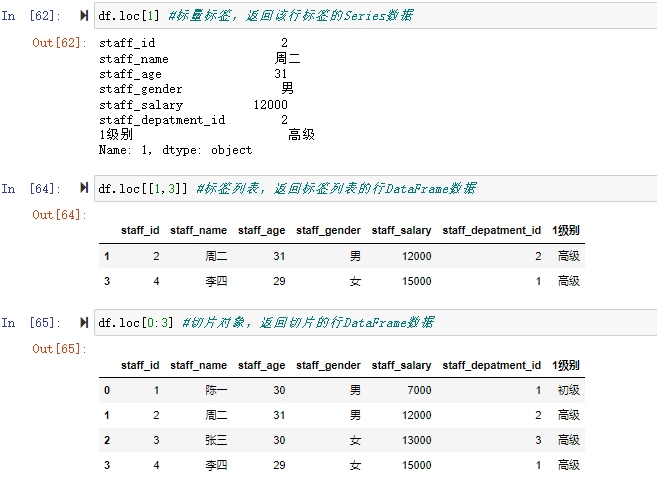
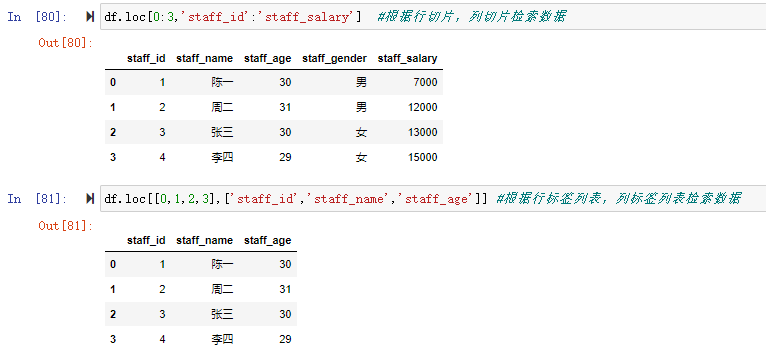
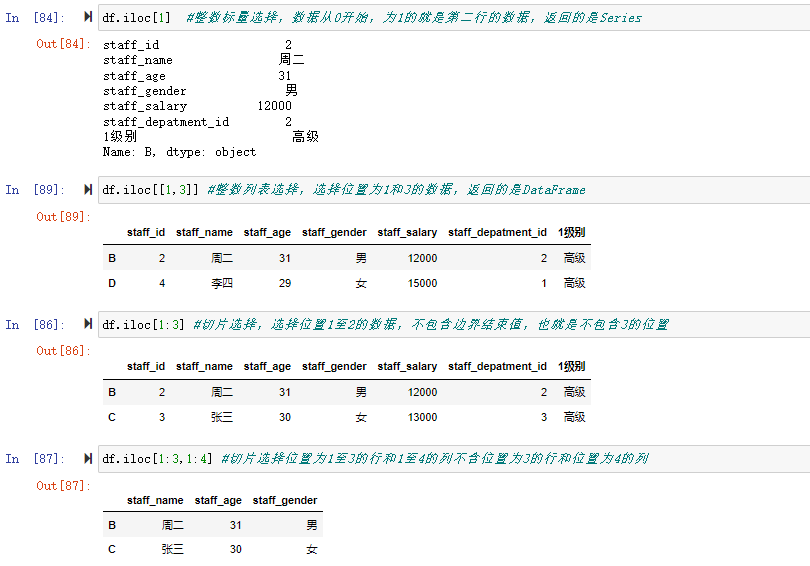
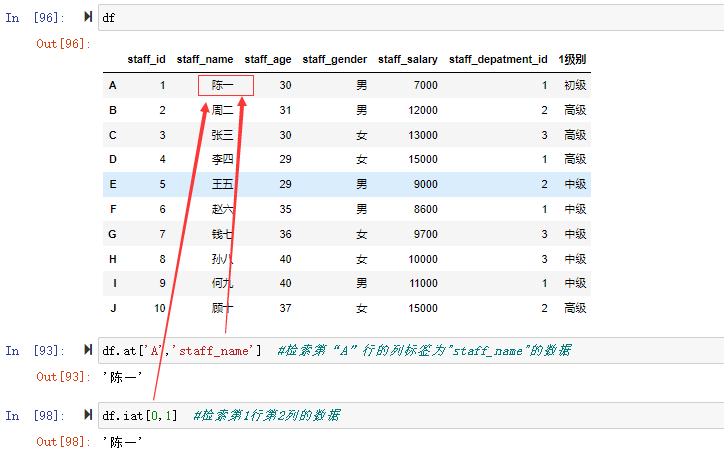
![[] 里用布尔条件进行检索](https://xiejava1018.github.io/xiejavaimagesrc/images/2022/20220207/%5B%5D%E6%9D%A1%E4%BB%B6.png)