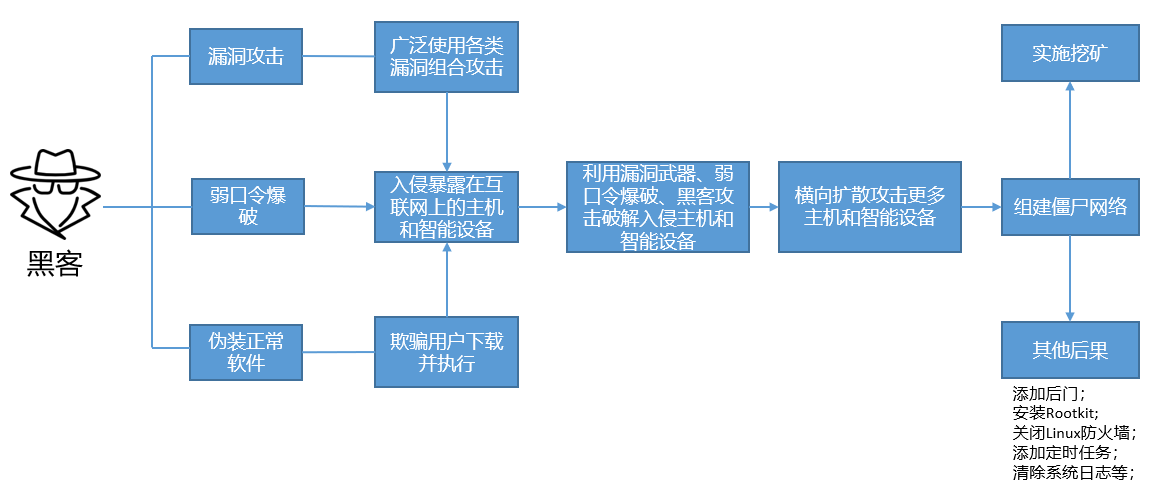
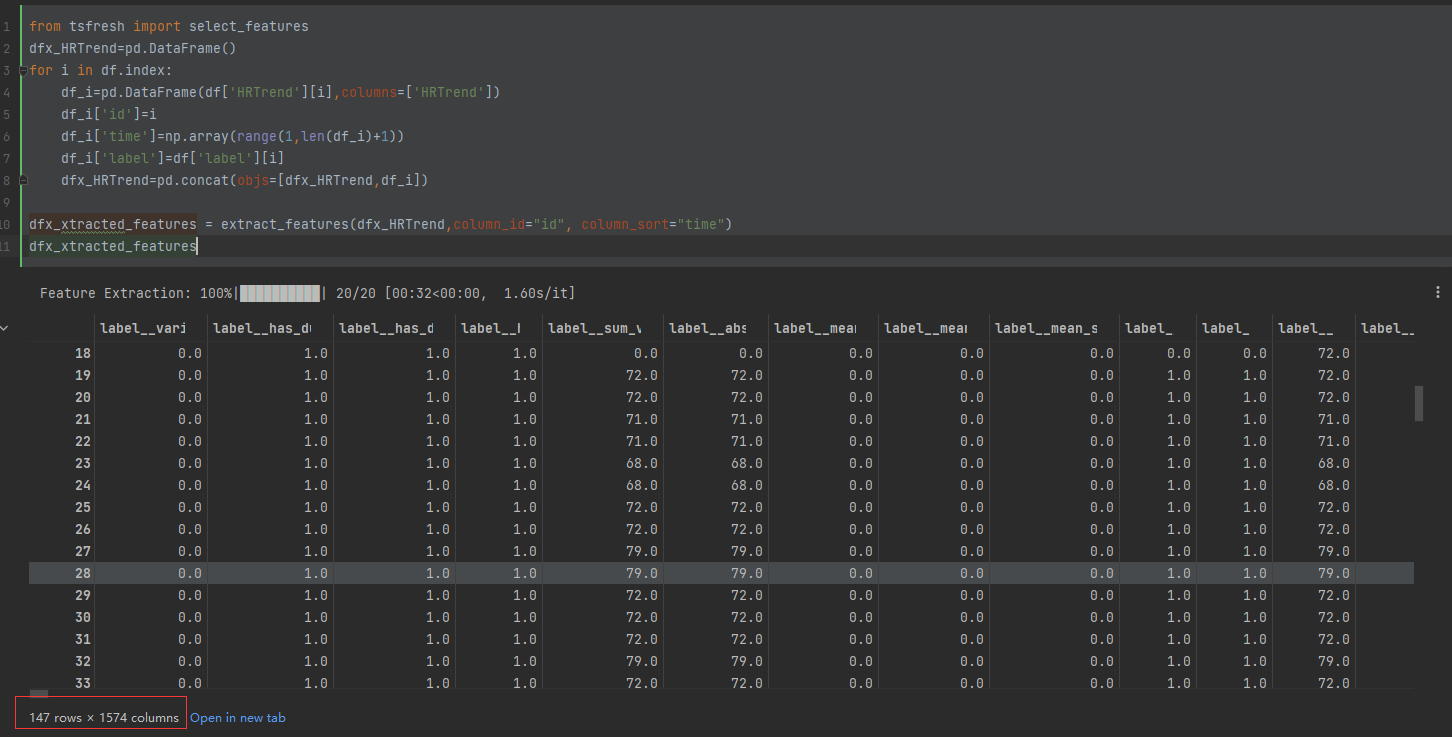
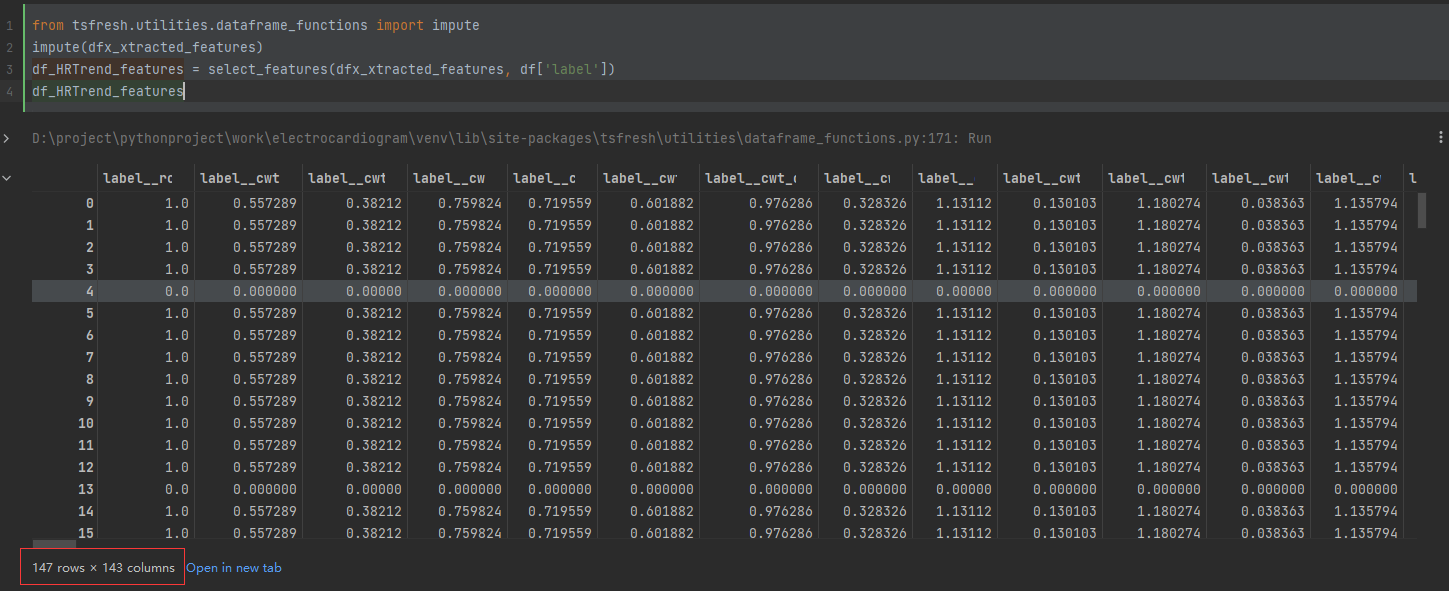
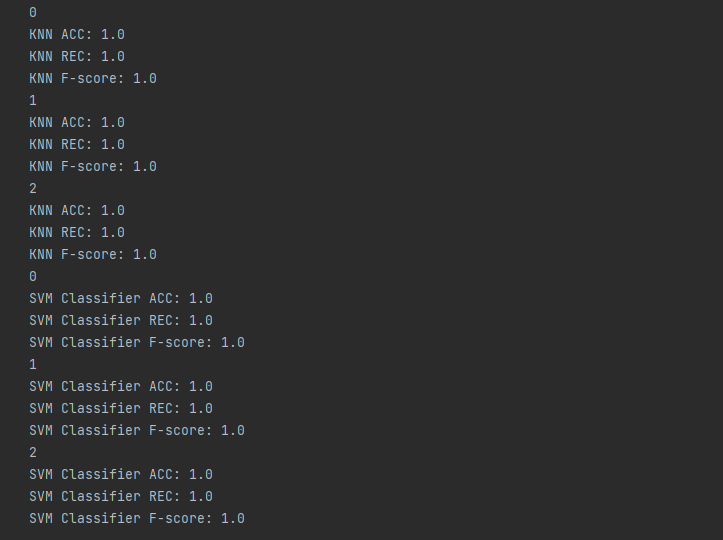
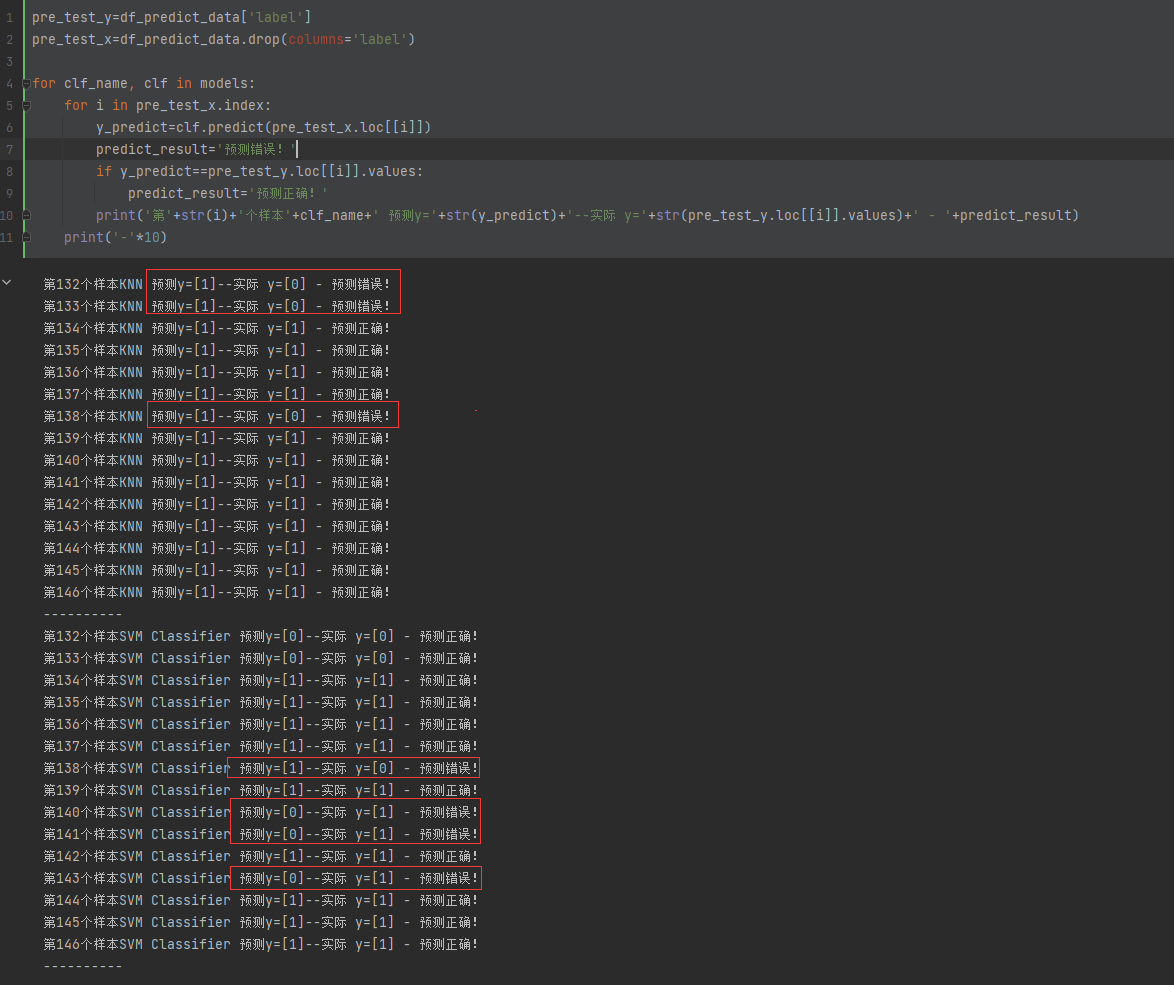
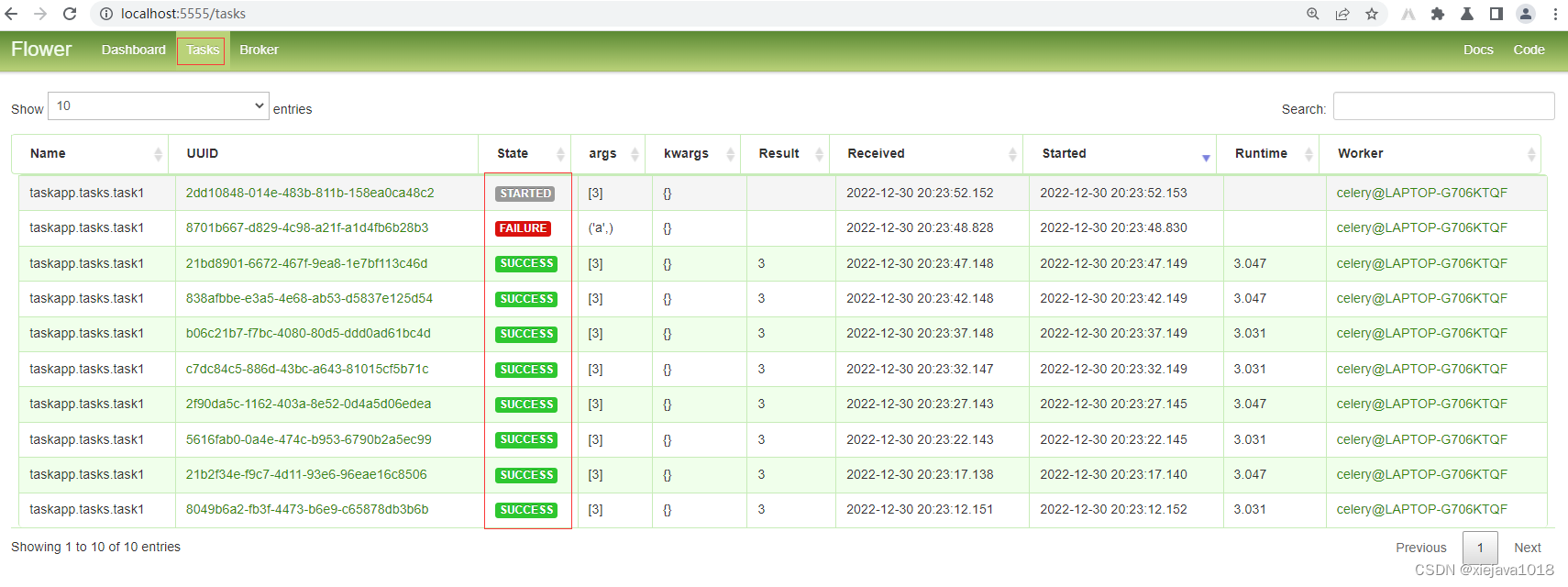
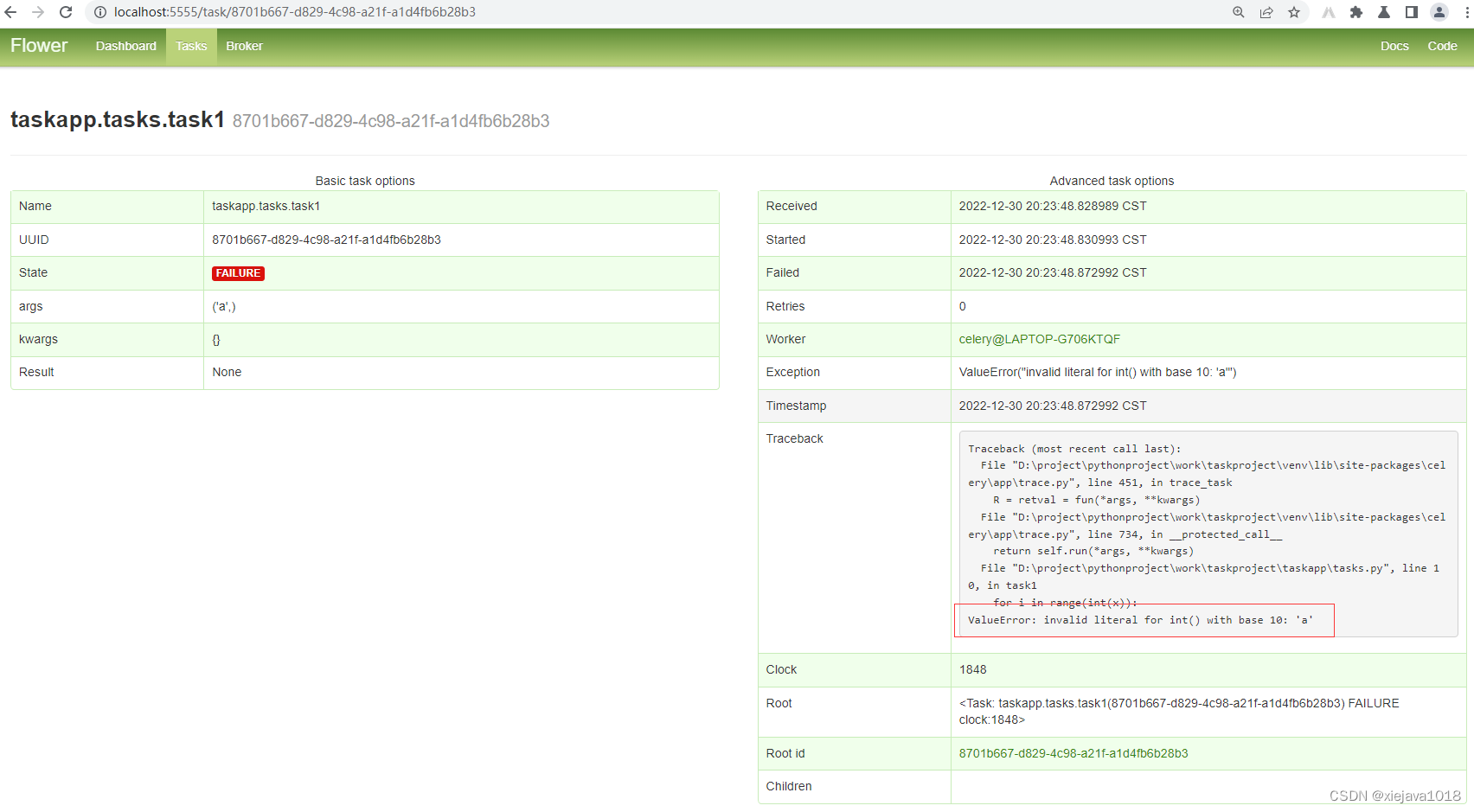
为保证业务系统运营的安全稳定,在业务系统上线前需要开展三同步检查,针对新业务系统上线、新版本上线、项目验收前开展安全评估。可以帮助其在技术层面了解系统存在的安全漏洞。今天就来了解一下安全评估之漏洞扫描、基线检查、渗透测试。
安全评估的内容主要涉及主机漏洞扫描、安全基线检查、渗透测试三个方面:
主机漏洞扫描
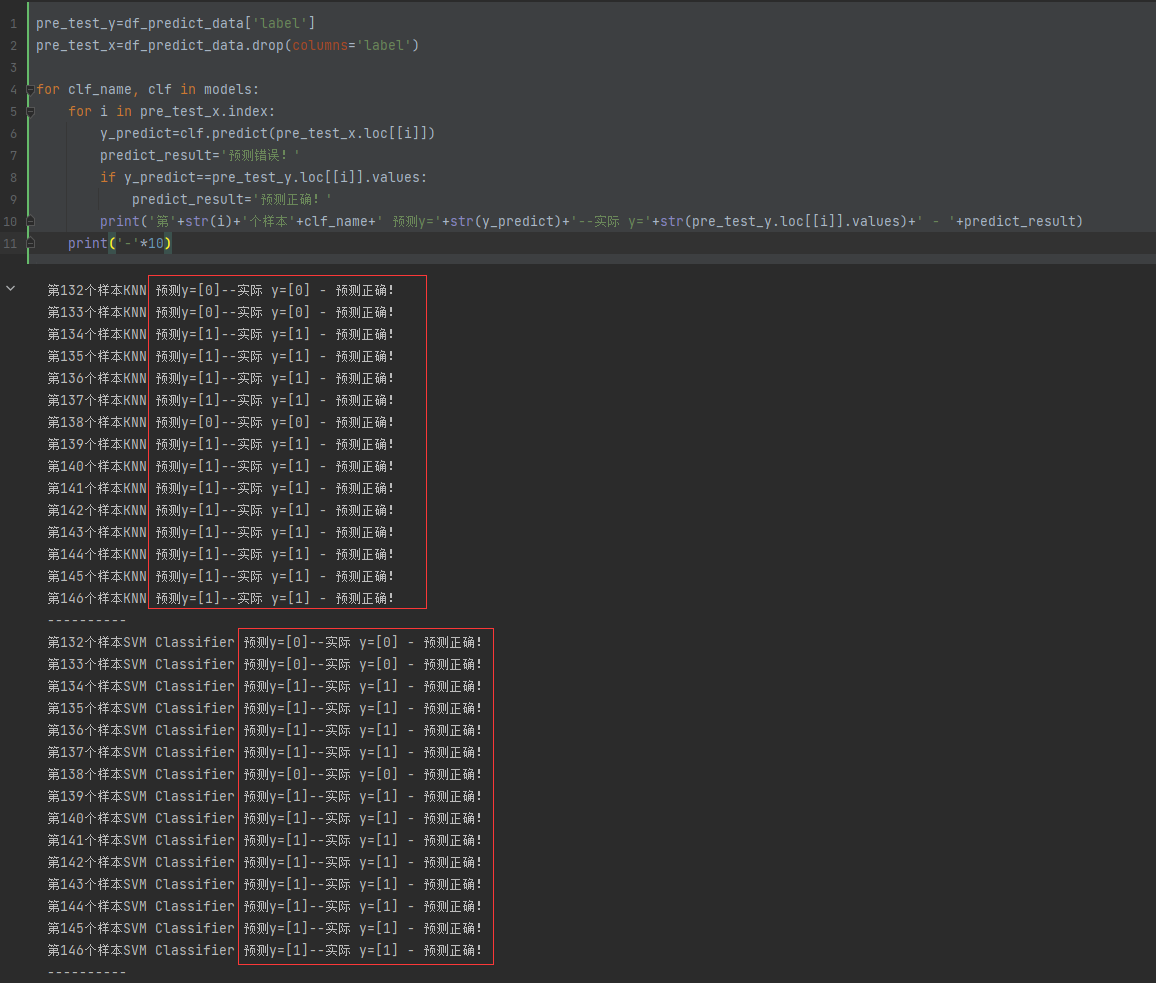
主机漏洞扫描一般是采用漏洞扫描工具,根据其内置的弱点测试方法,从网络侧对被评估对象进行一系列的检查,从而发现弱点。发现其存在的不安全漏洞后进行人工分析和确认,针对每个漏洞的整改意见完成报告的输出。被评估对象系统的管理人员根据扫描的结果以及修复建议修复网络安全漏洞,在黑客攻击前进行防范。被评估对象系统的管理人员对这些漏洞进行修复后,安服工程师会对漏洞扫描报告中每个漏洞进行漏洞复测,并输出复测报告。使用户更加全面的了解全网的安全状态,提高对安全漏洞的认识和管理能力,并通过对漏洞的修补加强应用系统抵御恶意入侵的能力。
安全基线检查
安全基线检查是通过采用安全检查设备以及人工检查两种方法从对应目标的安全合规性等方面开展对系统的全量安全基线检查,从而发现其基线的不合规项。其次在发现基线不合规项之后由安服工程师进行人工二次确认,依据工信部基线安全标准,针对性提供每个基线不合规项的整改建议,并完成基线不合规项报告输出。评估对象系统的管理人员可根据输出报告对基线不合规项进行基线整改。整改完成后,安服工程师会对按照工信部基线安全标准对所涉及不合规项进行安全基线复测,并输出复测报告。确保系统安全性得到提升,建立系统基础的安全防御体系。
渗透测试
渗透测试主要是模拟黑客的攻击手法,通过自动化漏洞扫描工具结合手工测试的方式对系统进行无害化的安全评估。渗透测试包含应用安全测试和业务安全测试两部分,应用安全测试包括但不限于如下内容:
| 序号 | 应用安全检查项 | 检查项说明 |
|---|---|---|
| 1 | 注入类攻击 | 注入攻击漏洞,例如SQL,OS以及LOAP注入,这些攻击发生在当不可信的数据作为命令或者查询语句的一部分,被发送给解释器的时候,攻击者发送的恶意数据可以欺骗解释器,以执行计划外的命令或者访问未授权的数据。 |
| 2 | 跨站脚本(XSS) | 当应用程序收到含有不可信的数据,在没有进行适当的验证和转义的情况下,就将它发送给一个网页浏览器,这就会产生跨站脚本攻击(简称XSS)。XSS允许攻击者在受害者的浏览器上执行脚本,从而劫持用户会话、危害网站、或者将用户转向恶意网站。 |
| 3 | 失效的身份认证和会话管理 | 与身份认证和会话管理相关的应用程序功能往往得不到正确的实现,这就导致了攻击者破坏密码、秘钥、会话令牌或攻击其他的漏洞去冒充其他用户的身份 |
| 4 | 不安全的直接对象引用 | 当开发人员暴露一个对内部实现对象的引用时,例如,一个文件、目录或数据库秘钥,就会产生一个不安全的直接对象引用,在没有访问控制检测或者其他保护时,攻击者会操作这些引用去访问未授权数据。 |
| 5 | 跨站请求伪造 | 一个跨站请求伪造攻击迫使登陆用户的浏览器将伪造的HTTP请求,包括该用户的会话cookie和其他认证信息,发送到一个存在漏洞的web应用程序,这就允许了攻击者迫使用户浏览器向存在漏洞的应用程序发送请求,而这些请求会被应用程序认为是用户的合法请求。 |
| 6 | 安全配置错误 | 好的安全需要对应用程序、框架、应用程序服务器、web服务器、数据库服务器和平台,定义和执行安全配置。由于许多设置的默认值并不是安全的,因此,必须定义、实施和维护所有这些设置。这包括了对所有的软件保持及时地更新,包括所有应用程序的库文件。 |
| 7 | 不安全的加密存储 | 许多web应用程序并没有使用恰当的加密措施或Hash算法保护敏刚数据,比如信用卡、身份证等等。攻击者可能利用这种弱保护数据实行身份盗窃、信用卡诈骗或其他犯罪。 |
| 8 | 没有限制URL访问 | 许多web应用程序在显示受保护的链接和按钮之前会检测URL访问权限。但是,当这些页面被访问是,应用程序也需要执行类似的访问控制检测,否则攻击者将可以伪造这些URL去访问隐藏的页面 |
| 9 | 传输层的保护不足 | 应用程序时常没有进行身份认证,加密措施,甚至没有保护敏感网络数据的保密性和完整性。而当进行保护时,应用程序有时采用弱算法,使用过期或者无效的证书,或不正确地使用这些技术。 |
| 10 | 未验证的重定向和转发 | WEB应用程序经常将用户重新定向和转发到其他网页和网站,并且利用不可信的数据去判定目的页面,如果没有得到适当验证,攻击者可以重定向受害用户到钓鱼软件或恶意网站,或者使用转发去访问未授权的页面 |
业务安全测试包括但不限于如下内容:
| 序号 | 业务安全检查项 | 检查项说明 |
|---|---|---|
| 1 | 身份认证管理 | 该项测试主要针对身份认证环节,以及在非授权情况下访问一些授权用户才能访问的页面,或进行授权用户的操作。 |
| 2 | 业务一致性 | 该项测试主要针对办理业务过程中用户的身份与用户办理的业务是否相关联一直的安全测试 |
| 3 | 业务授权安全 | 该项测试主要针对于是否存在非授权情况下访问一些授权用户才能访问的页面,或进行授权用户的操作。 |
| 4 | 用户输入合法性验证 | Web应用程序没有对用户输入数据的合法性进行判断,就会使应用程序存在安全隐患。从而容易受到跨站脚本及SQL注入等攻击 |
| 5 | 误操作回退 | 手动进行误操作尝试,看系统是否能够正确回滚。例如,交易操作,在购买未完成时异常退出,看系统是否能够自动释放被购买物的锁定状态。又例如办理操作,如话费套餐变更,更改过程出错或异常退出是否能正确回滚到办理之前的状态 |
| 6 | 验证码机制 | 验证码控制是一种由WEB应用程序生成的随机数,以确保用户提交的请求不是由bot生成。 |
| 7 | 业务数据篡改 | 该项测试主要针对于办理业务过程中用户浏览器端传递至服务端的字段篡改测试。 |
| 8 | 业务流乱序 | 该项测试主要针对业务的处理流程是否有正常的顺序,确保不会通过技术手段绕过某些重要流程步骤。 |
| 9 | 信息正确呈现 | 对于用户提交的请求,是否能够返回用户需要的页面信息。 |
| 10 | 业务接口恶意调用 | 1.对于敏感的业务接口,是否预先有身份认证机制?查看此类可能被恶意大规模调用的业务接口,如用户登录模块、密码找回、密码重置等等。 2.对于具有查询展示办理功能的业务皆苦,如果不需要身份认证是否有强制验证码机制防止机器人程序等自动化大规模的恶意调用。 |
博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!