一直以来都想把我的文档都集中起来建一套知识库,方便统一的搜索查询和调用。我用过很多的文档编写管理工具有在线的、离线的,包括有有道云笔记、语雀、飞书、Notion、Obsidian等。这些工具编写管理文档还可以但是要做为一个知识库还远远不够。我认为知识库不但要解决“知识存哪里” 的问题,更要解决 “知识怎么用” 的痛点,能够将多源的知识内容进行聚合,方便检索查询和使用。
我需要的知识库系统能够具备以下能力:
- 多源内容聚合的能力:能够将我的博客网站、飞书、语雀、离线的文档等都能导入到知识库中。
- 方便快捷的搜索能力:AI辅助搜索,能够随时快速找到我想要的东西,AI辅助问答,能够基于已有的知识快速给出比较靠谱的答案。
- 便捷强大的编辑能力:能够通过富文本、Markdown随时记录文本,通过AI来辅助创作。
几番比较找到了PandaWiki,这款开源AI大模型驱动的知识库搭建系统,我觉得满足了目前我对知识库的要求,其安装方便、使用便捷、免费开源,零成本就能拥有自己的AI知识库,目前在github上斩获了8.4K的Star说明了受欢迎的程度。
一、什么是PandaWiki
PandaWiki 是一款 AI 大模型驱动的开源知识库搭建系统,帮助你快速构建智能化的 产品文档、技术文档、FAQ、博客系统,借助大模型的力量为你提供 AI 创作、AI 问答、AI 搜索等能力,具备富文本编辑、第三方集成和内容导入能力,采用AGPL-3.0开源协议。
它的核心价值在于将 AI 能力与知识库深度融合,不仅解决了 “知识存哪里” 的问题,更攻克了 “知识怎么用” 的痛点。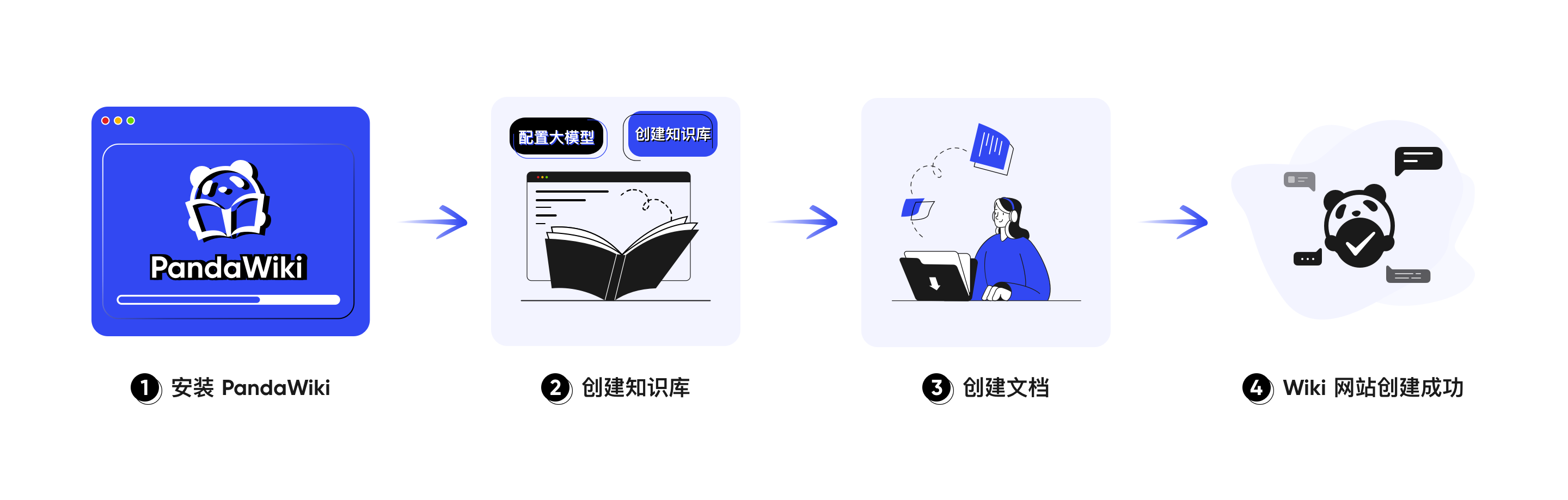
PandaWiki 的功能设计围绕 “智能化” 与 “便捷性” 展开,核心可概括为三大 AI 功能与五大实用特性,覆盖知识库从搭建到使用的全场景需求:
| 类别 | 具体功能 | 价值说明 |
|---|---|---|
| AI 核心功能 | AI 创作 | 辅助生成、优化文档内容,降低内容生产门槛,提升写作效率 |
| AI 问答 | 支持用户以自然语言提问,AI 基于知识库内容精准作答,而非返回杂乱链接 | |
| AI 搜索 | 依托 AI 大模型实现语义化搜索,精准匹配用户需求,解决传统关键词搜索的局限性 | |
| 实用特性 | 富文本编辑 | 支持 Markdown 与 HTML 语法,满足不同用户编辑习惯;文档可导出为 Word、PDF、Markdown 格式 |
| 多渠道内容导入 | 支持通过飞书文档、Notion、URL、Sitemap、RSS 及离线文件导入内容,省去重复复制粘贴操作 | |
| 第三方平台集成 | 可接入钉钉、飞书、企业微信、Discord 等平台的聊天机器人,实现 “随处查知识” | |
| 高度自定义 | 支持配置 Wiki 网站配色、背景图、水印、页脚(企业名称、ICP 备案、品牌 Logo 等),打造专属风格 | |
| 数据统计与反馈 | 管理后台可实时查看 Wiki 网站的访问次数、用户分布、问答记录及反馈信息,便于优化内容 |
PandaWiki 的最大优势之一是 “低门槛”—— 无需复杂代码开发,提供了一键部署安装脚本,全程耗时不超过 5 分钟,即使是非技术人员也能轻松上手。
二、PandaWiki的安装部署
1、部署前的准备
PandaWiki的官方文档见 https://pandawiki.docs.baizhi.cloud/node/01971602-bb4e-7c90-99df-6d3c38cfd6d5
PandaWiki安装需Linux系统、x86_64架构,依赖Docker 20.10.14+和Docker Compose 2.0.0+,推荐1核2G内存10G磁盘。
安装 PandaWiki 系统环境要求如下:
- 操作系统:Linux
- CPU 指令架构:x86_64、aarch64
- 软件依赖:Docker 20.10.14 版本以上
- 软件依赖:Docker Compose 2.0.0 版本以上
- 推荐配置:2 核 CPU / 4 GB 内存 / 20 GB 磁盘
- 最低配置:1 核 CPU / 2 GB 内存 / 5 GB 磁盘
我的配置是ubuntu系统2核CPU/4GB内存/100GB磁盘。
2、安装PandaWiki
官方提供了一键自动安装命令,可以非常便捷无脑的就把系统给装上。
使用 root 权限登录你的服务器,然后执行以下命令。
1 | bash -c "$(curl -fsSLk https://release.baizhi.cloud/panda-wiki/manager.sh)" |
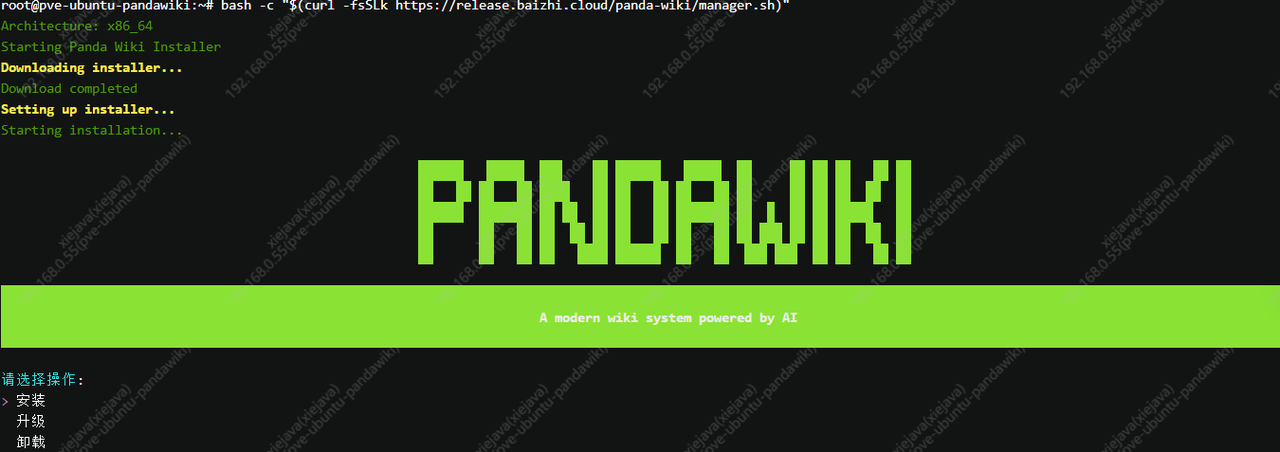
选择“安装”,回车
系统检测到没有安装docker,输入“y”,系统自动安装docker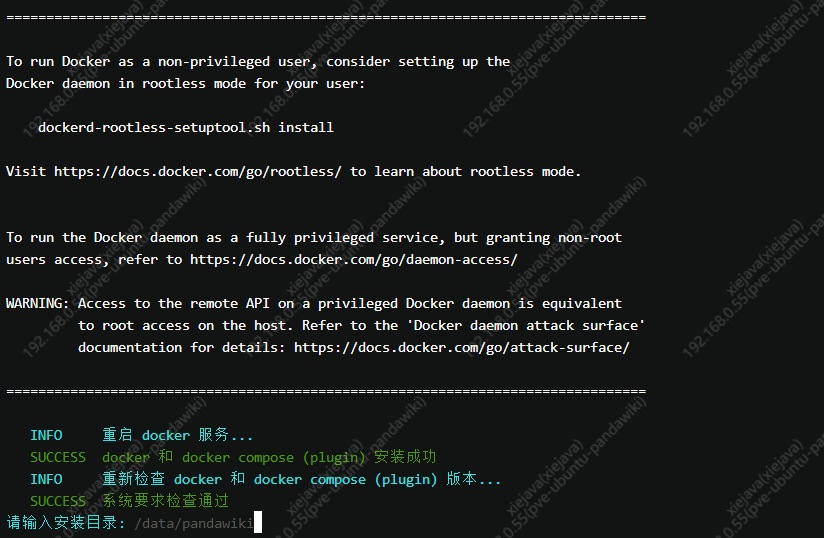
默认安装路径位于 /data/pandawiki
到显示所有容器安装完成并启动就会显示如下信息
1 | SUCCESS 控制台信息: |
修改默认密码
如果需要修改admin的密码可以修改安装目录下.env文件中的 ADMIN_PASSWORD 后,执行
bash docker compose up -d即可生效。
使用浏览器打开上述内容中的 “访问地址”,就可以看到 PandaWiki 的控制台登录入口。
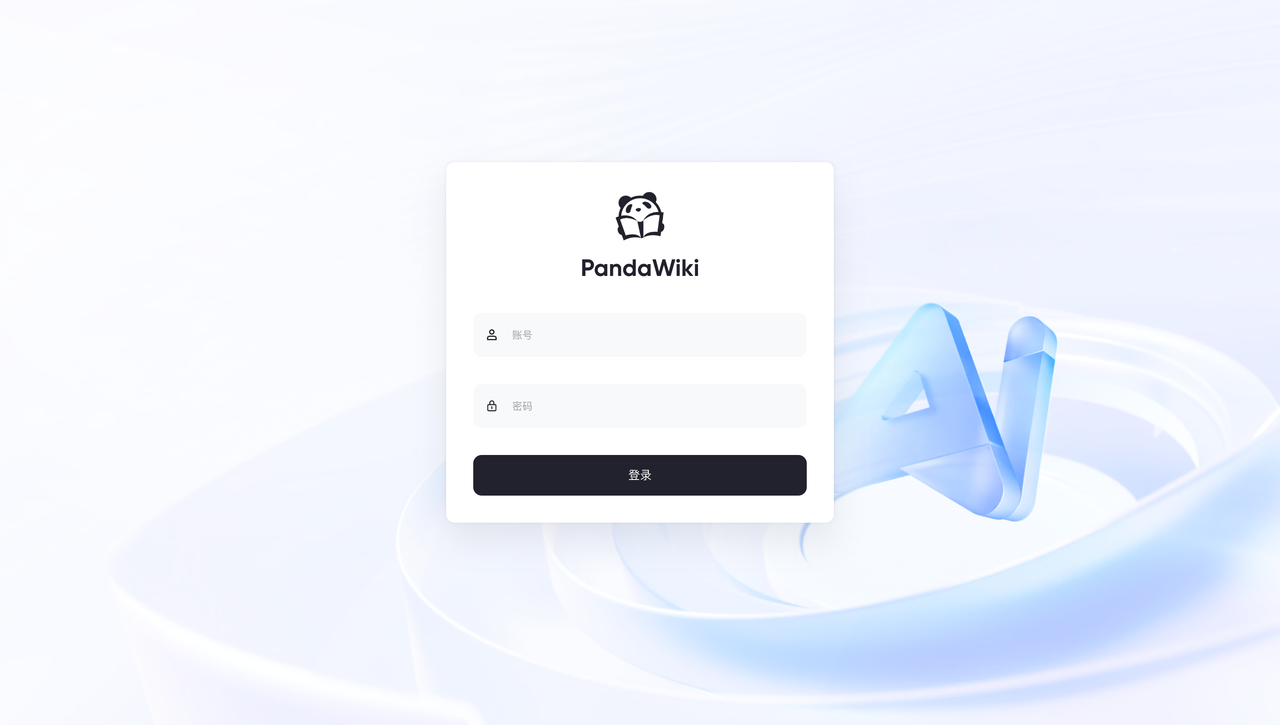
三、PandaWiki的使用
1、配置 AI 大模型
由于 PandaWiki 的 AI 功能(创作、问答、搜索)均依赖 AI 大模型,首次使用需先完成模型配置,否则相关功能无法正常使用。其支持的模型类型及推荐方案如下:
- Chat 模型:用于对话与内容生成,如 ChatGPT-4、Deepseek-r1、Deepseek-v3 等
- Embedding 模型:将文档转化为向量,支撑智能搜索与内容关联,如 BGE-M3
- Reranker 模型:对搜索结果二次排序,提升检索精准度,如 BGE-Reranker-V2-M3
我这里直接使用PandaWiki默认的模型“自动配置”。自动配置需要点击“获取百智云API Key”来获取API Key,注册登录百智云就可以获取5元的免费额度。当然通过手动配置用其他的模型API也可以。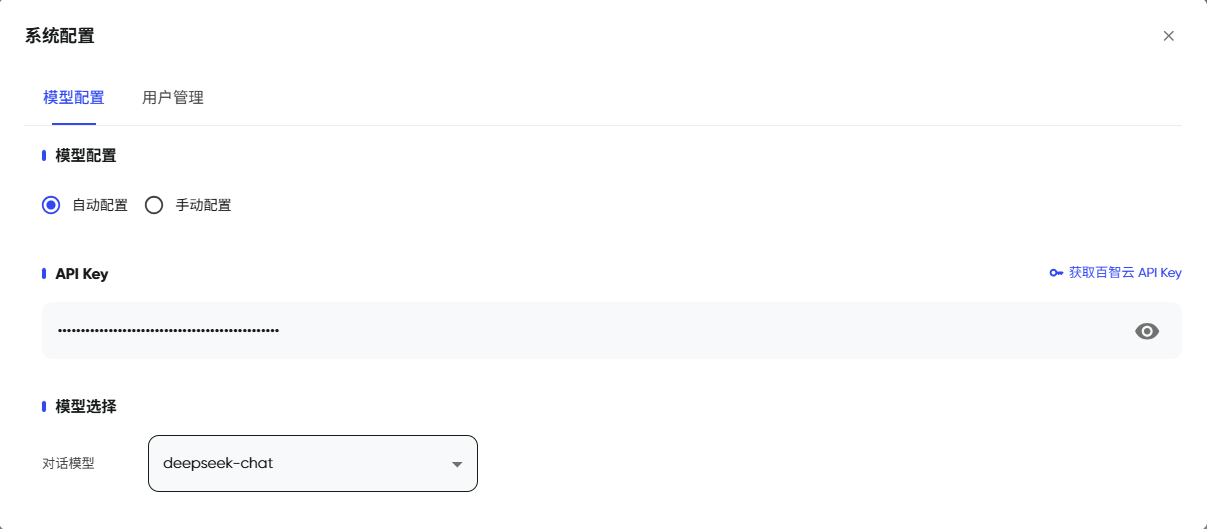
2、启用创建门户网站
启用创建门户网站PandaWiki会自动帮创建一个门户网站,可以自定义门户网站的模板,“启用HTTP”输入暴露的端口80就可以开启门户网站,注意不要和2443端口重了,2443是后台admin的管理服务。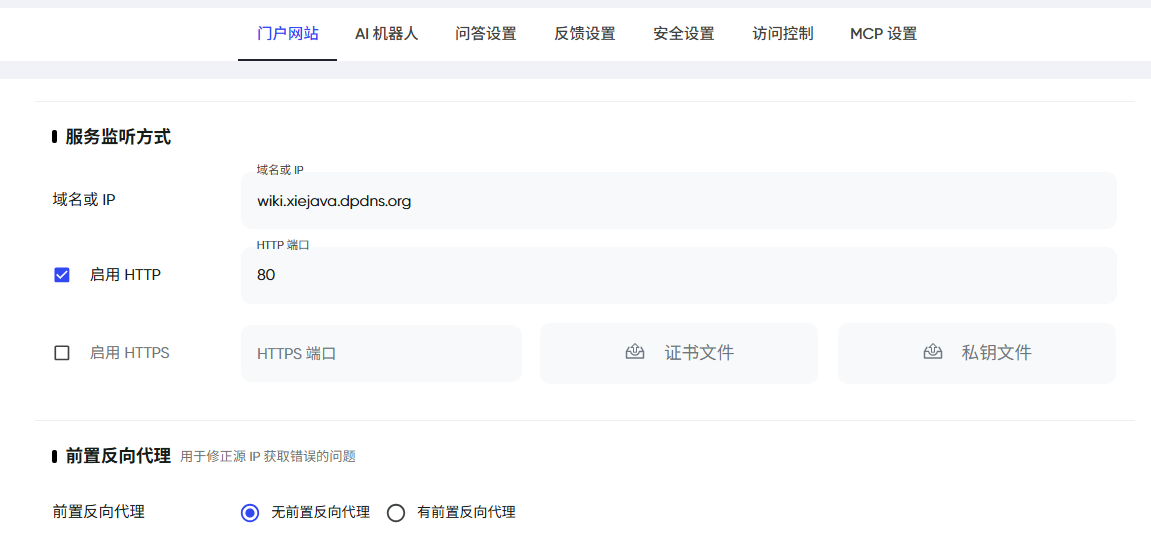
通过简单的配置就可以生成一个wiki网站,如果有域名就可以通过域名访问了,没有域名就通过IP访问。
我这里配了域名,可以通过wiki.xiejava.dpdns.org访问。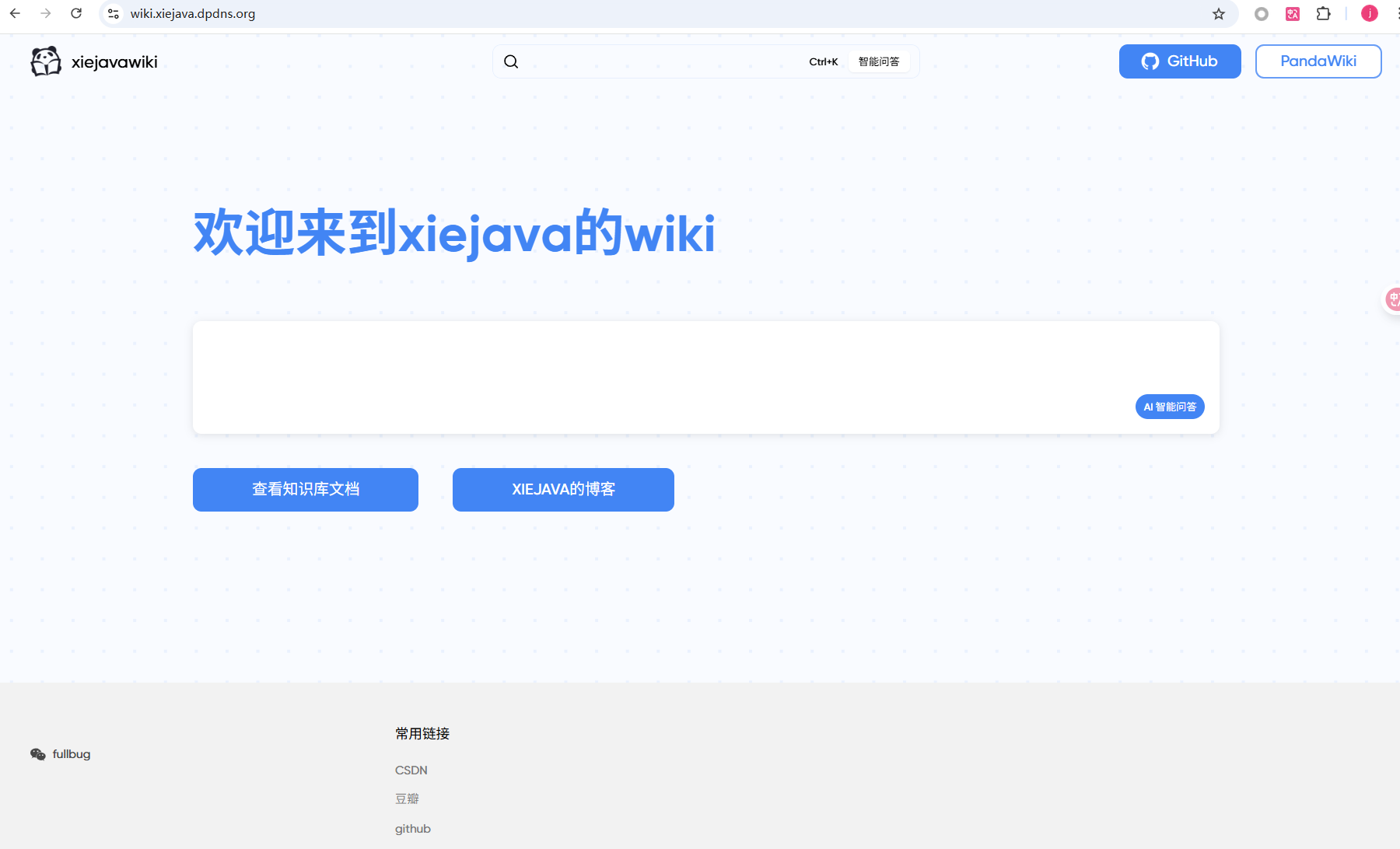
3、导入文档到PandaWiki创建知识库
PandaWiki 支持从第三方文档中导入文档,目前支持以下几种方式
- 通过离线文件导入
- 通过 URL 导入
- 通过 RSS 导入
- 通过 Sitemap 导入
- 通过 Notion 导入
- 通过 Epub 导入
- 通过 MiniDoc 导入
- 通过 Wiki.js 导入
- 通过 Confluence 导入
- 通过飞书文档导入
- 通过语雀导入
- 通过思源笔记导入
官方都有详细的说明文档
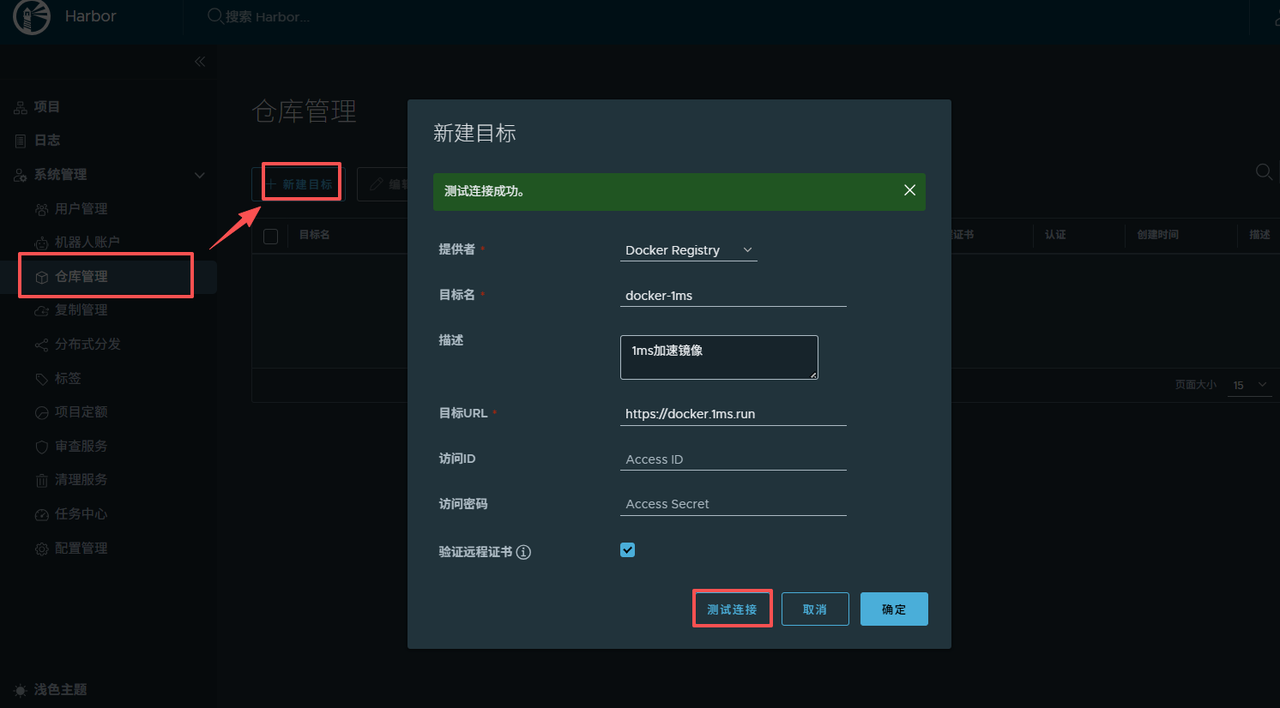
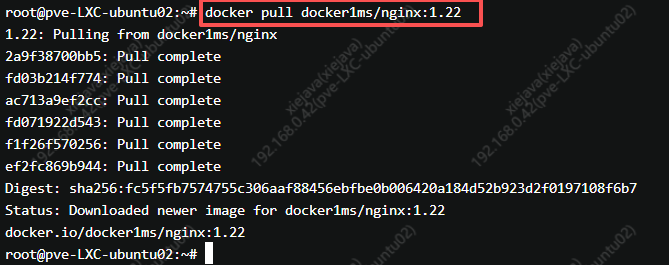
我这里将我的博客文档通过离线方式进行导入。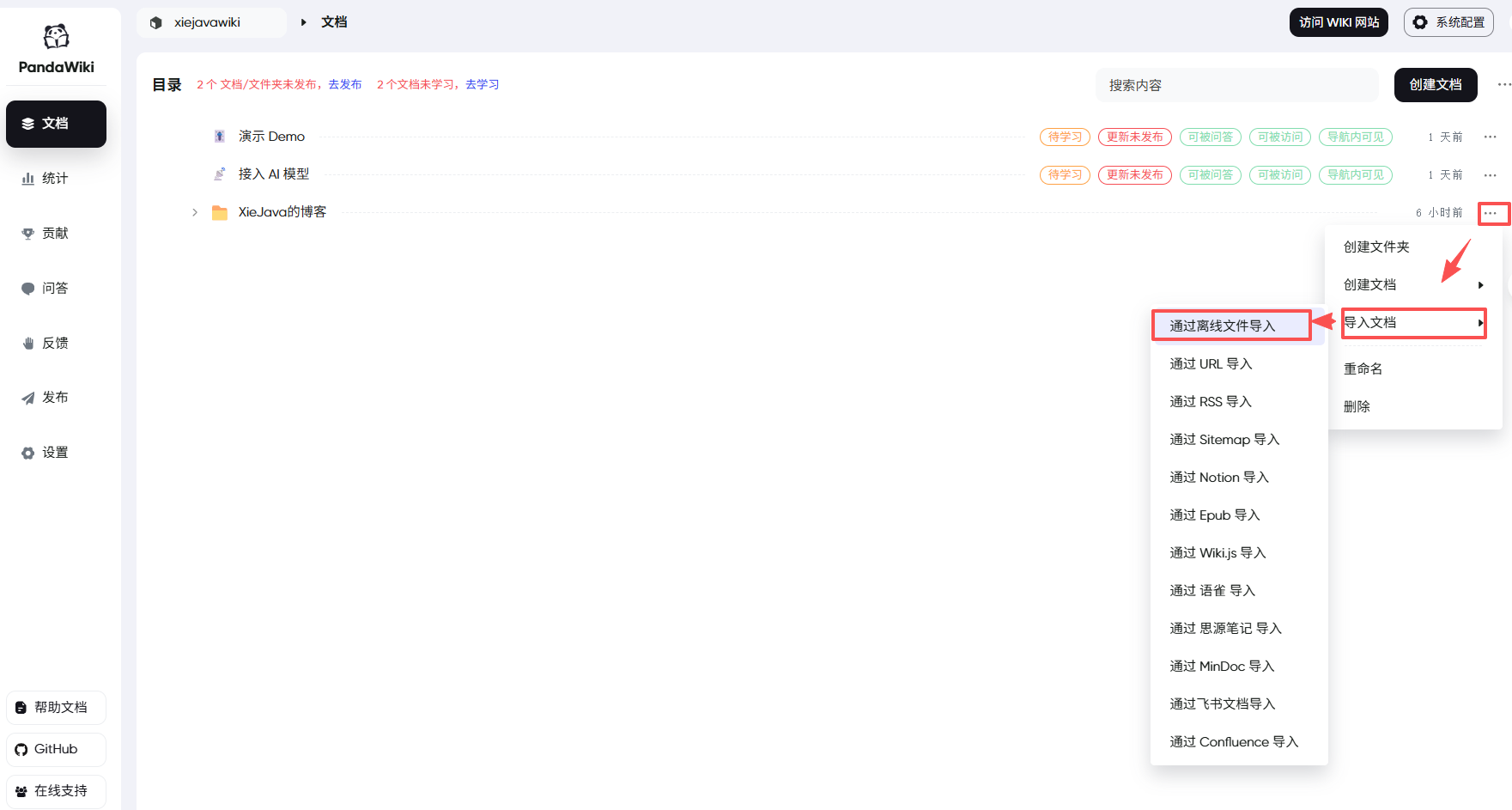
在离线文件导入界面选择要导入的文件,支持的格式包括.txt、.md、.xlx、.xlsx、.docx、.pdf 。
注意:每个文件的大小不能超过 20 MB。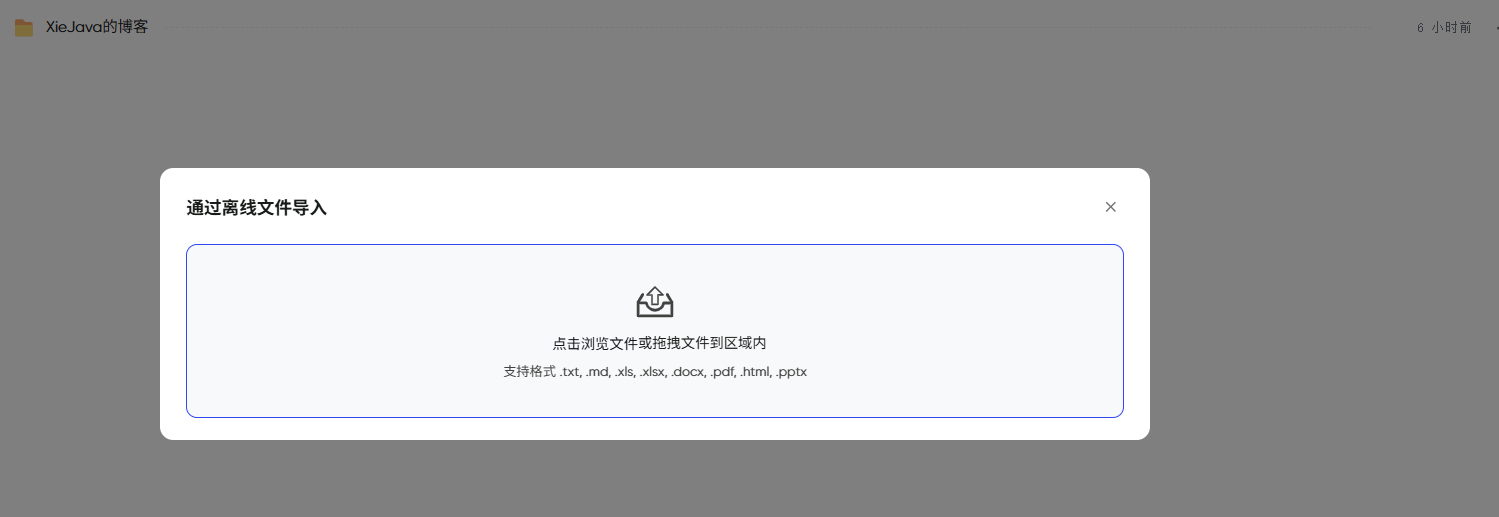
选择要导入的文件后,会对.md文件自动进行解析。
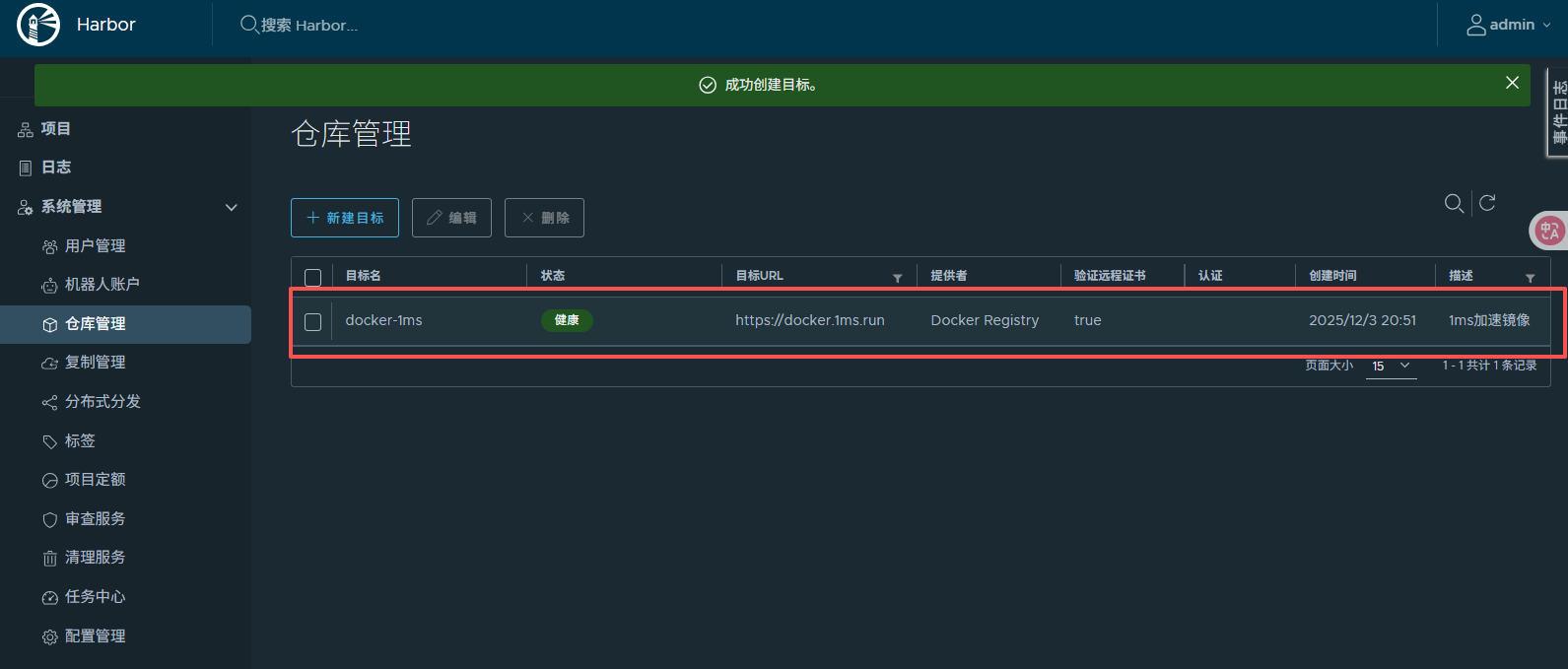
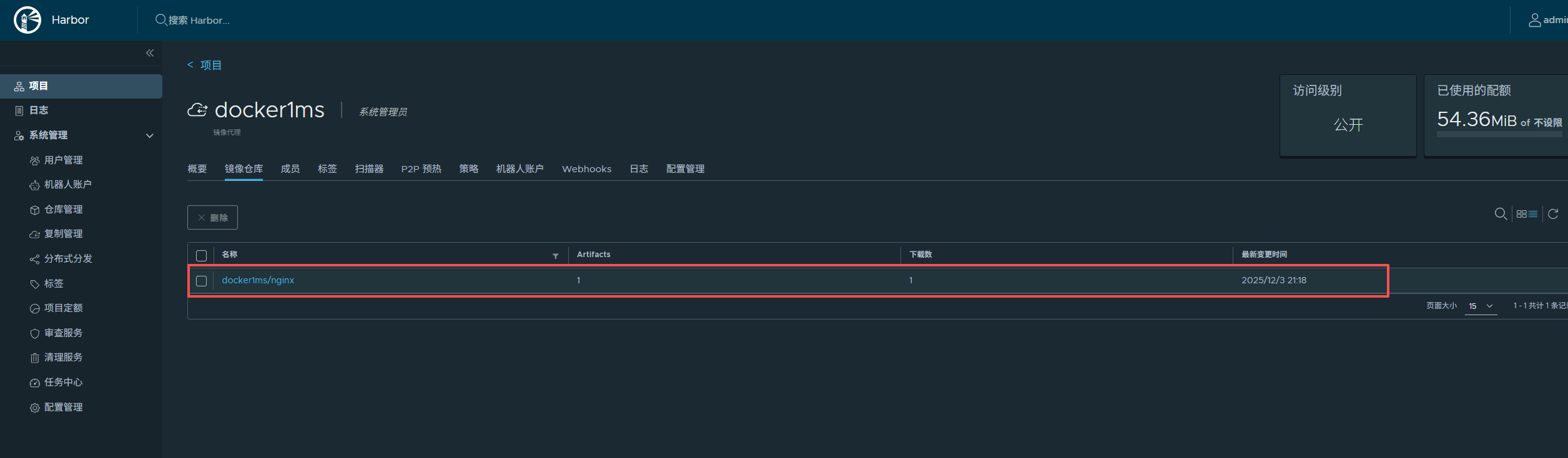
解析完了点击“批量导入”,就可以将文件导入到知识库,并且展示的是解析后的富文本形式。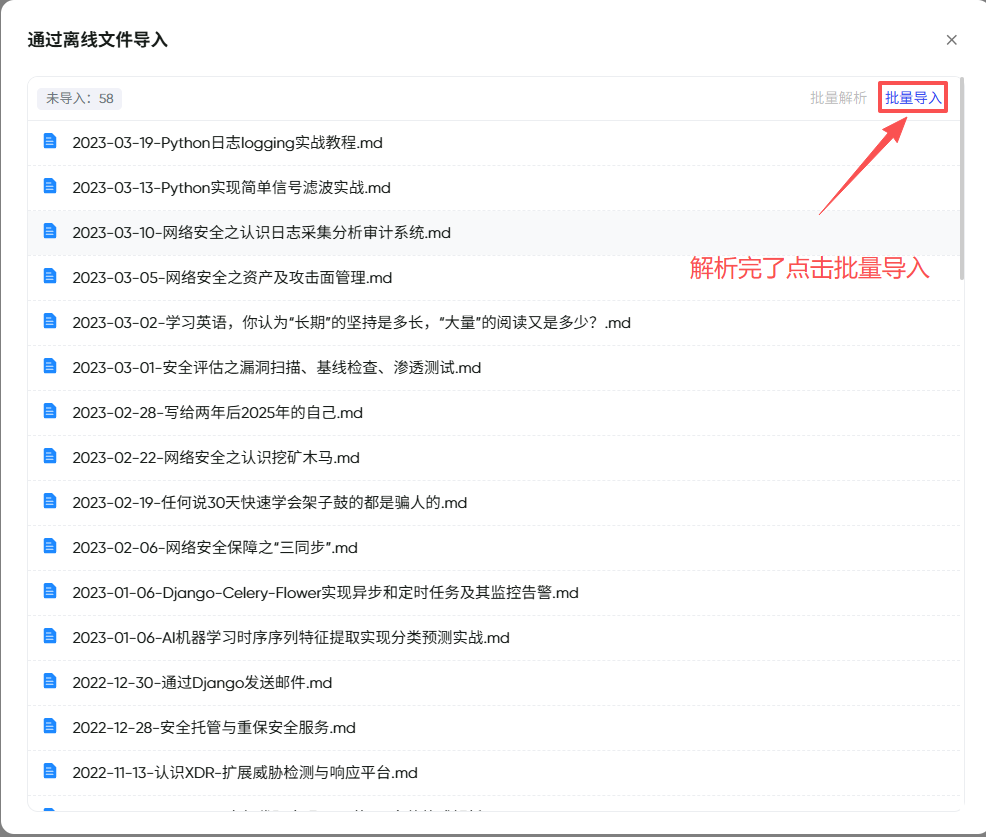
批量导入处理中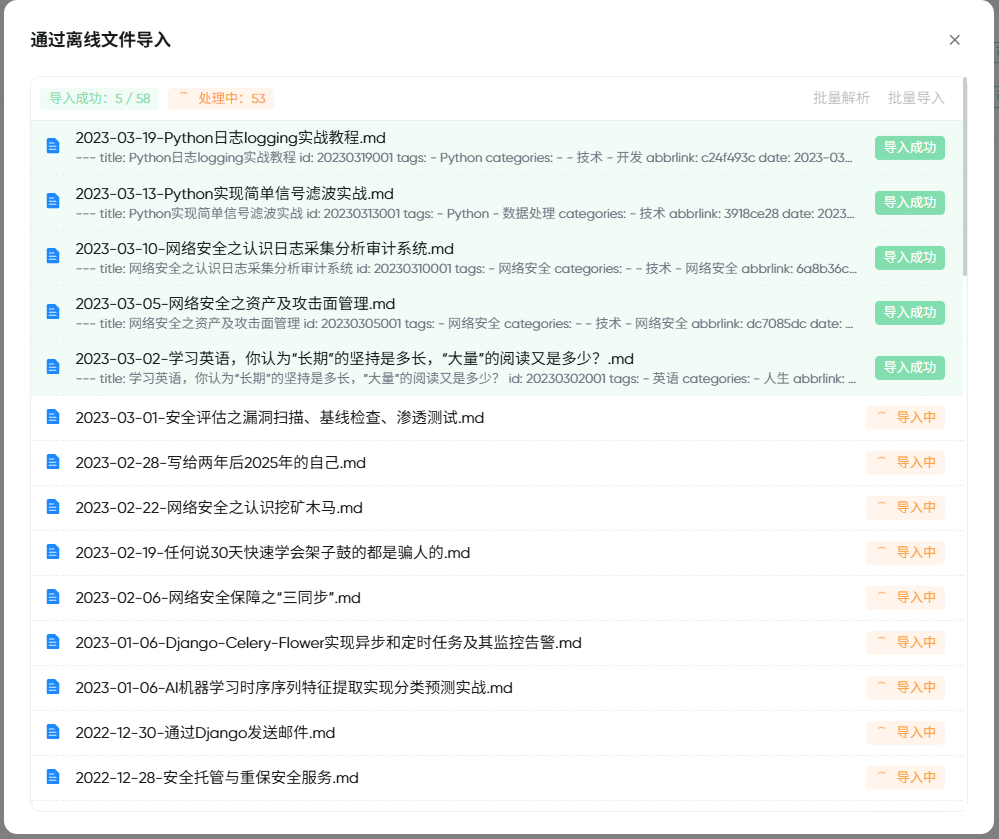
新导入的文件虽然是可以被可见、被访问、被问答,但是还没有进行增强学习处理需要进一步的学习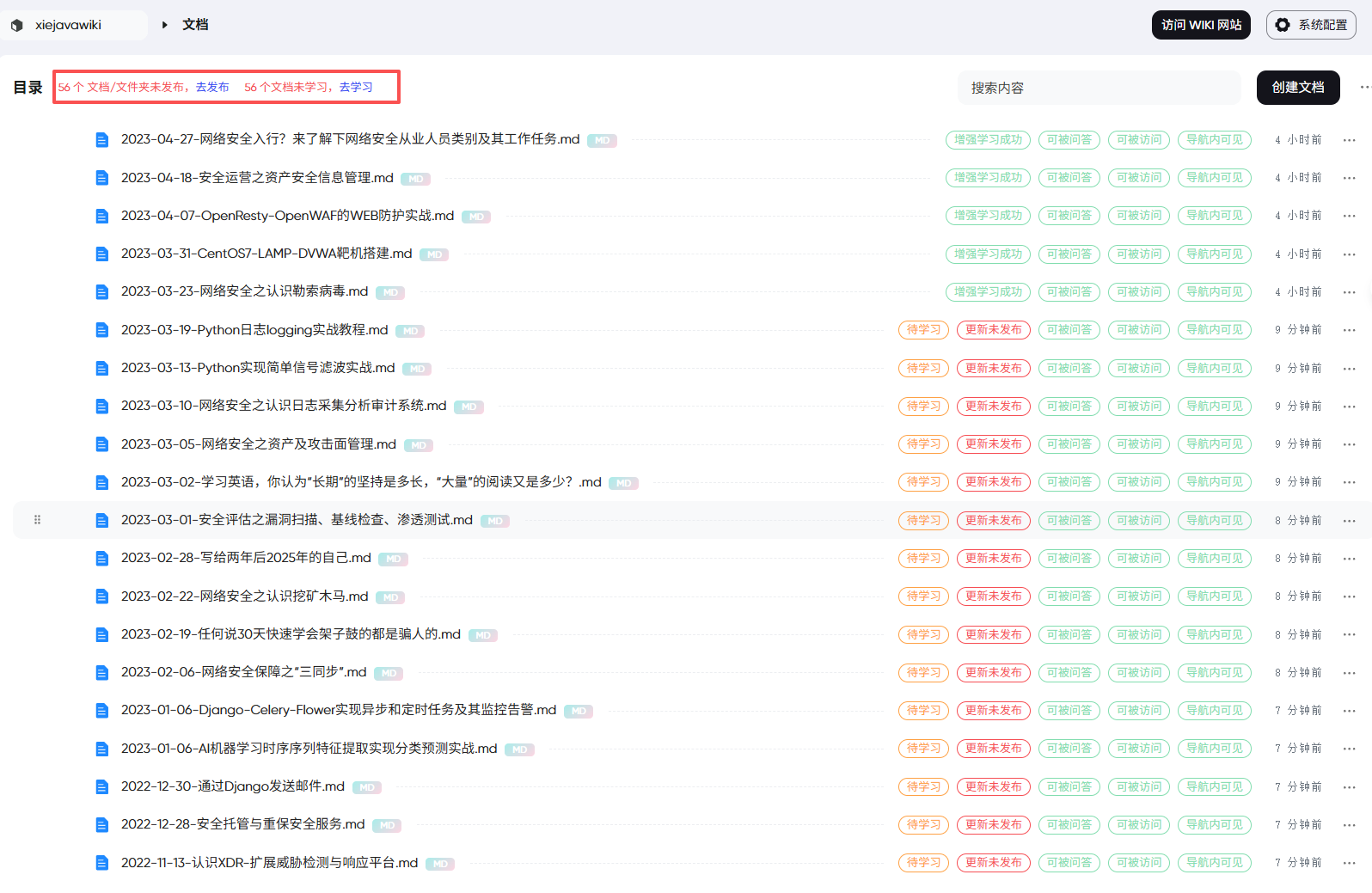
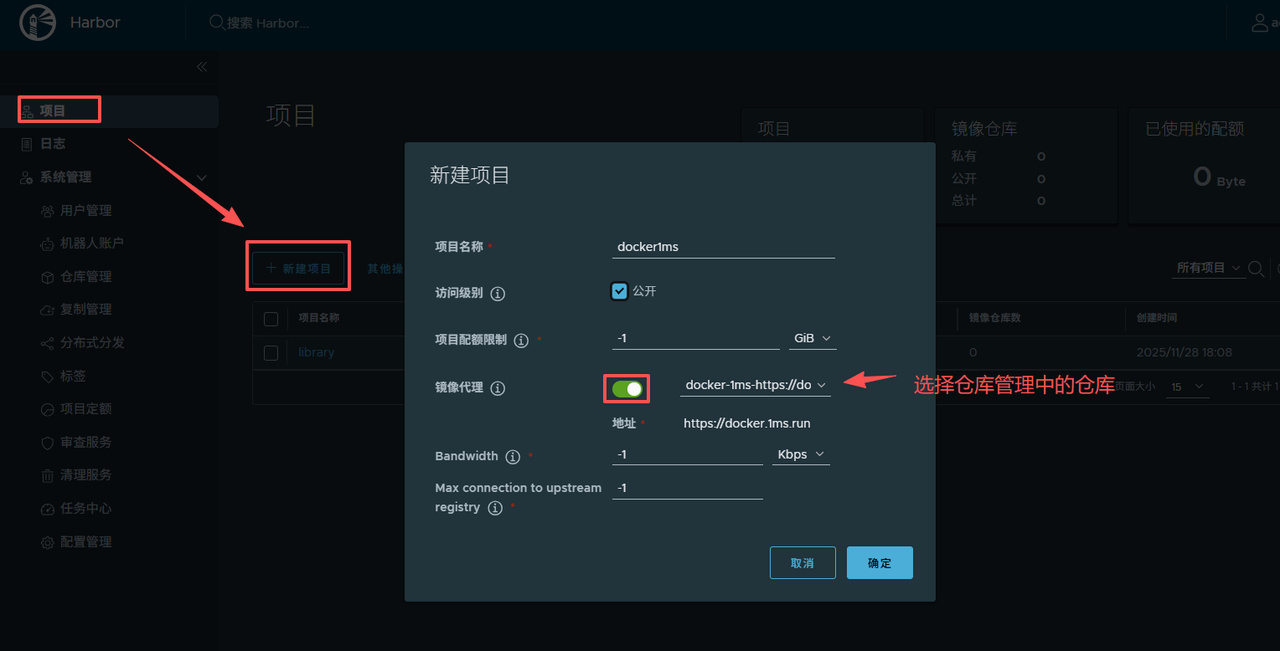
PandaWiki的文档处理状态如下图:
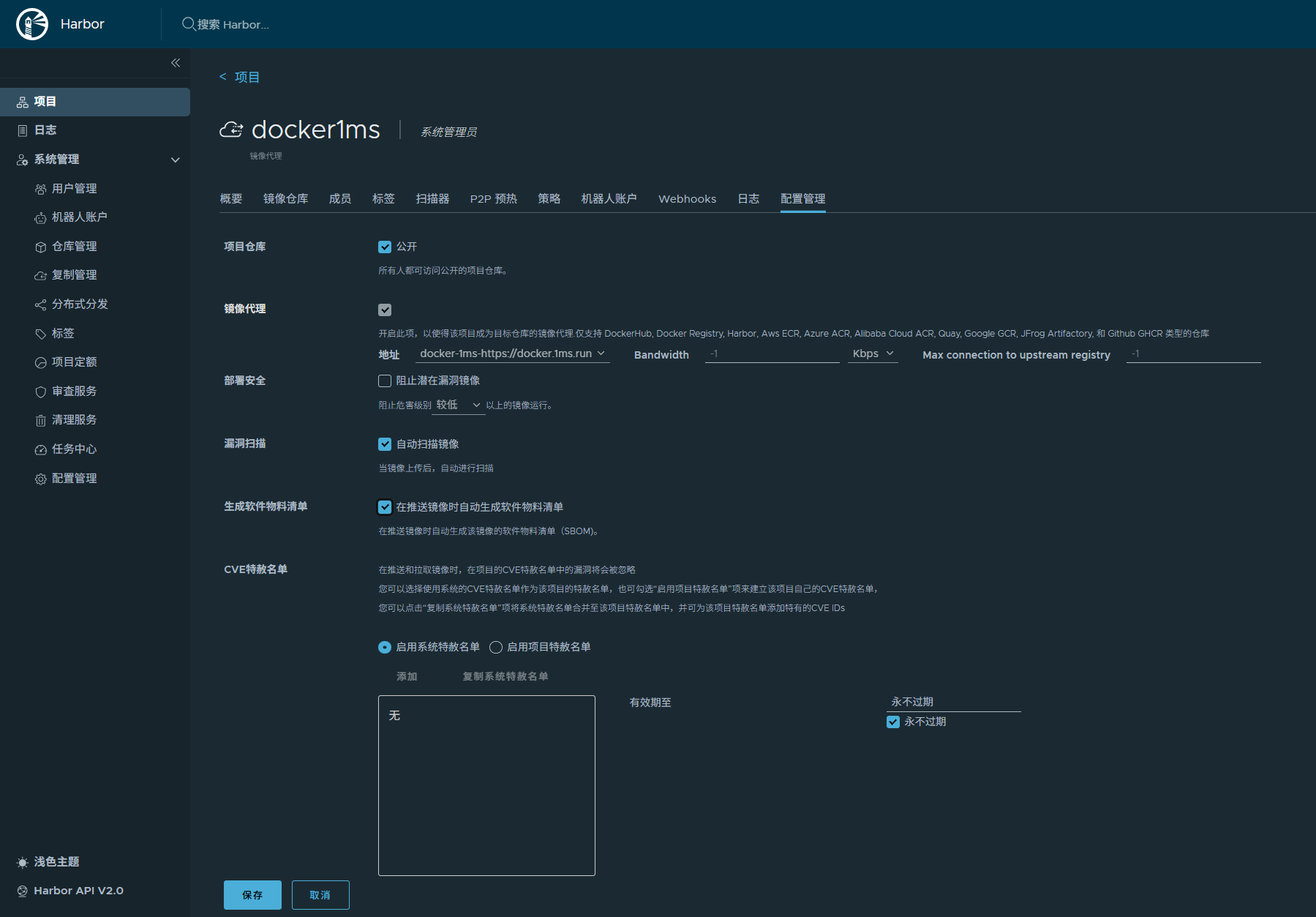
选择需要学习的文档点“确认”进行学习
当学习和发布完成后,可以在web门户网站进行AI检索和AI问答了。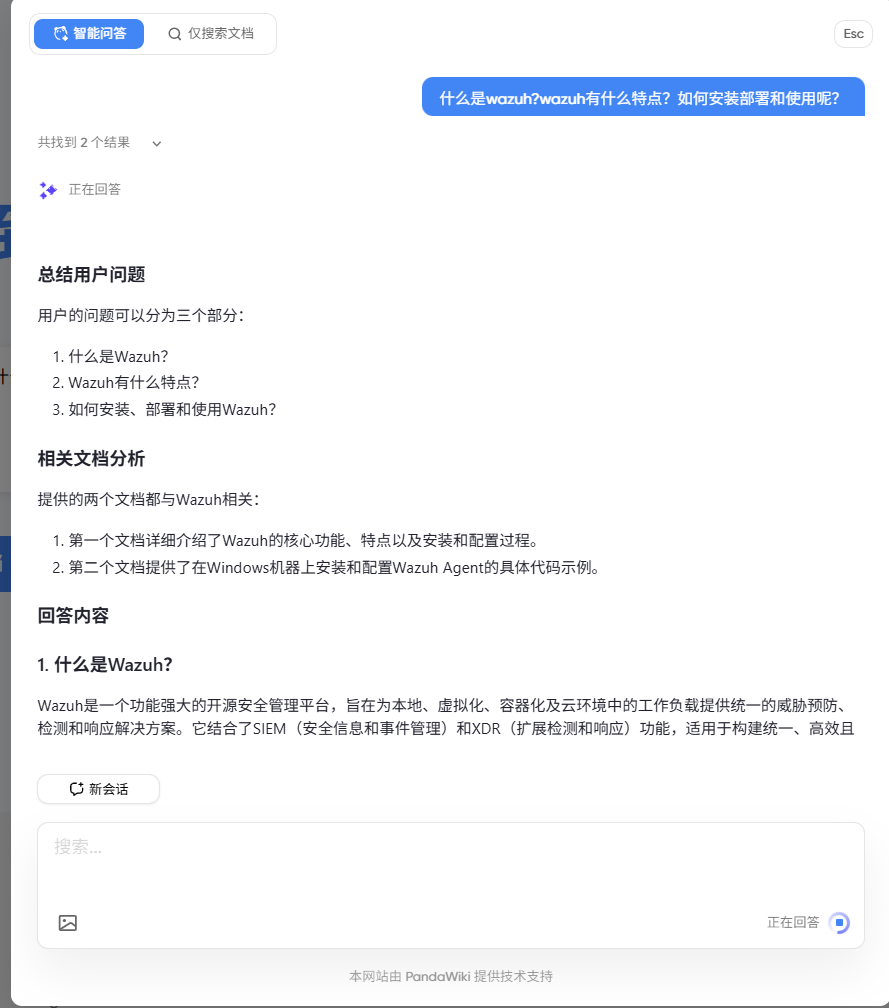

我们可以将pandawiki直接当一个博客网站来使用,它对markdown的解析和展示还挺好的。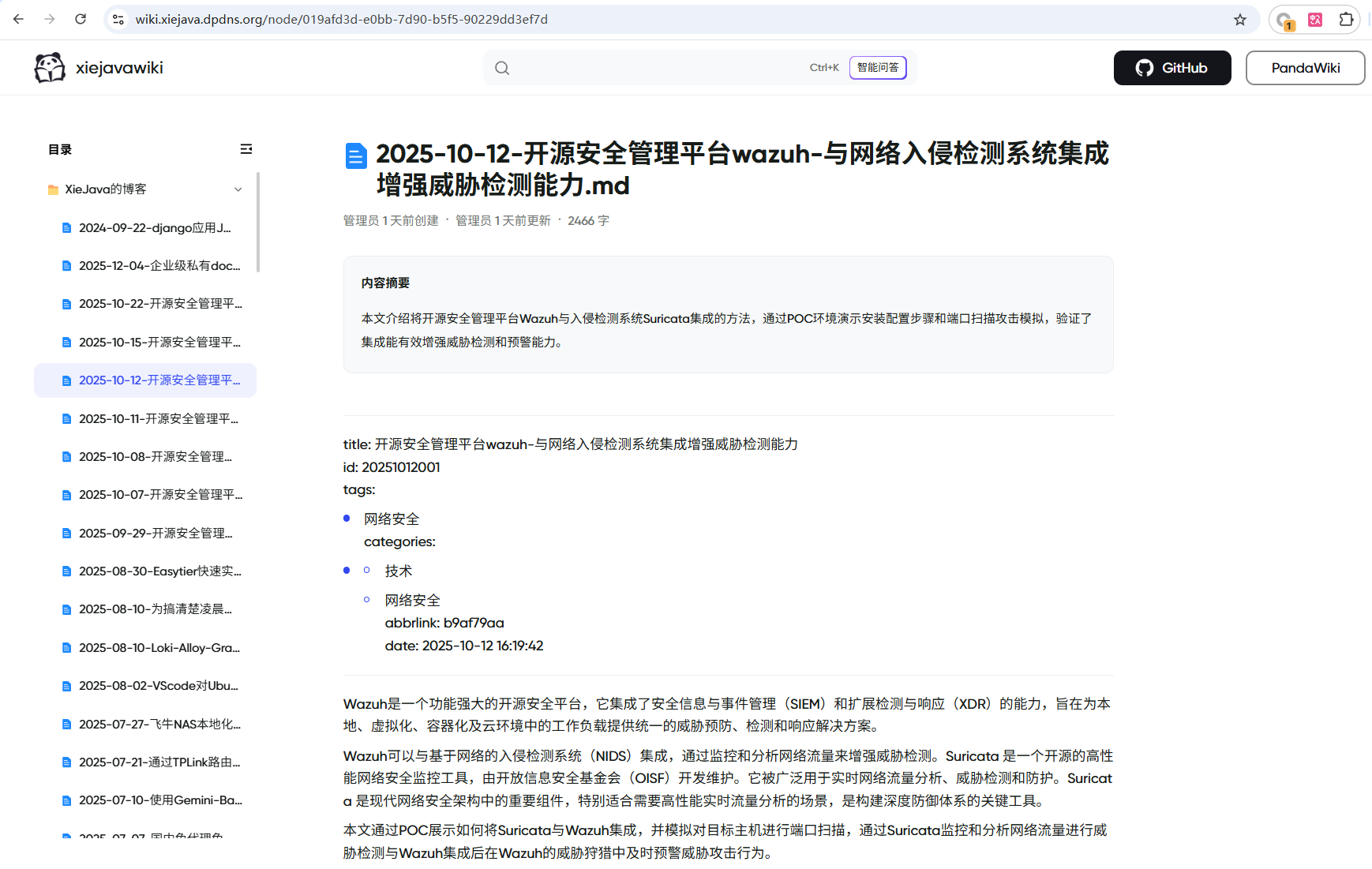
欢迎访问我的wiki站点 https://wiki.xiejava.dpdns.org 在这里我将和你一起分享IT技术,感受AI带来的便捷。
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!


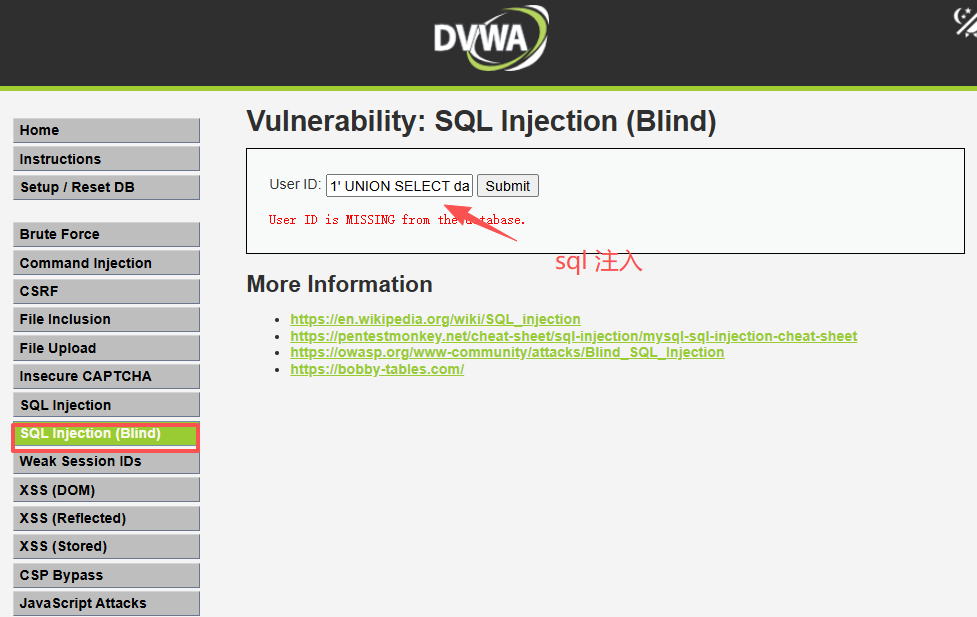
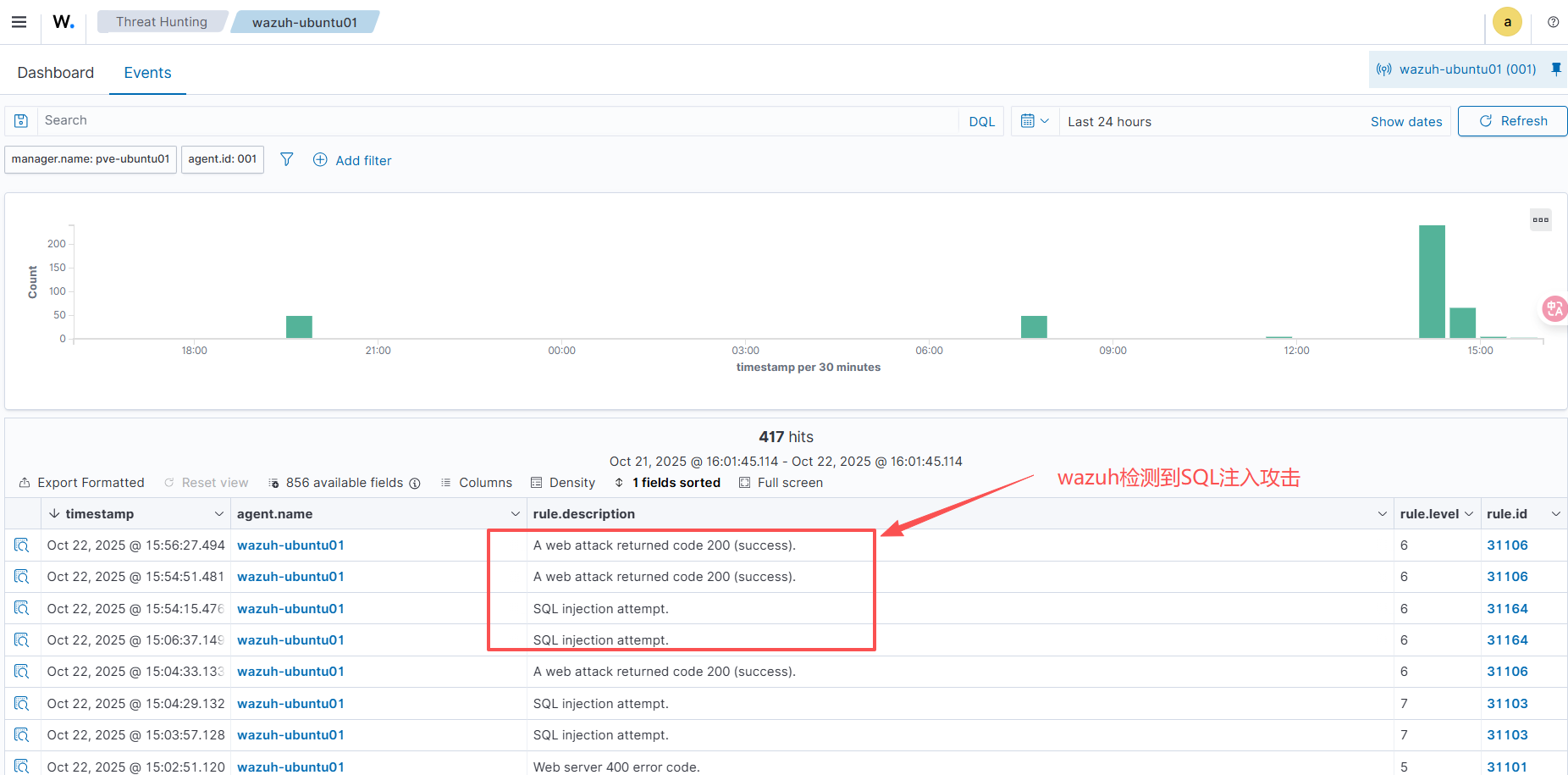
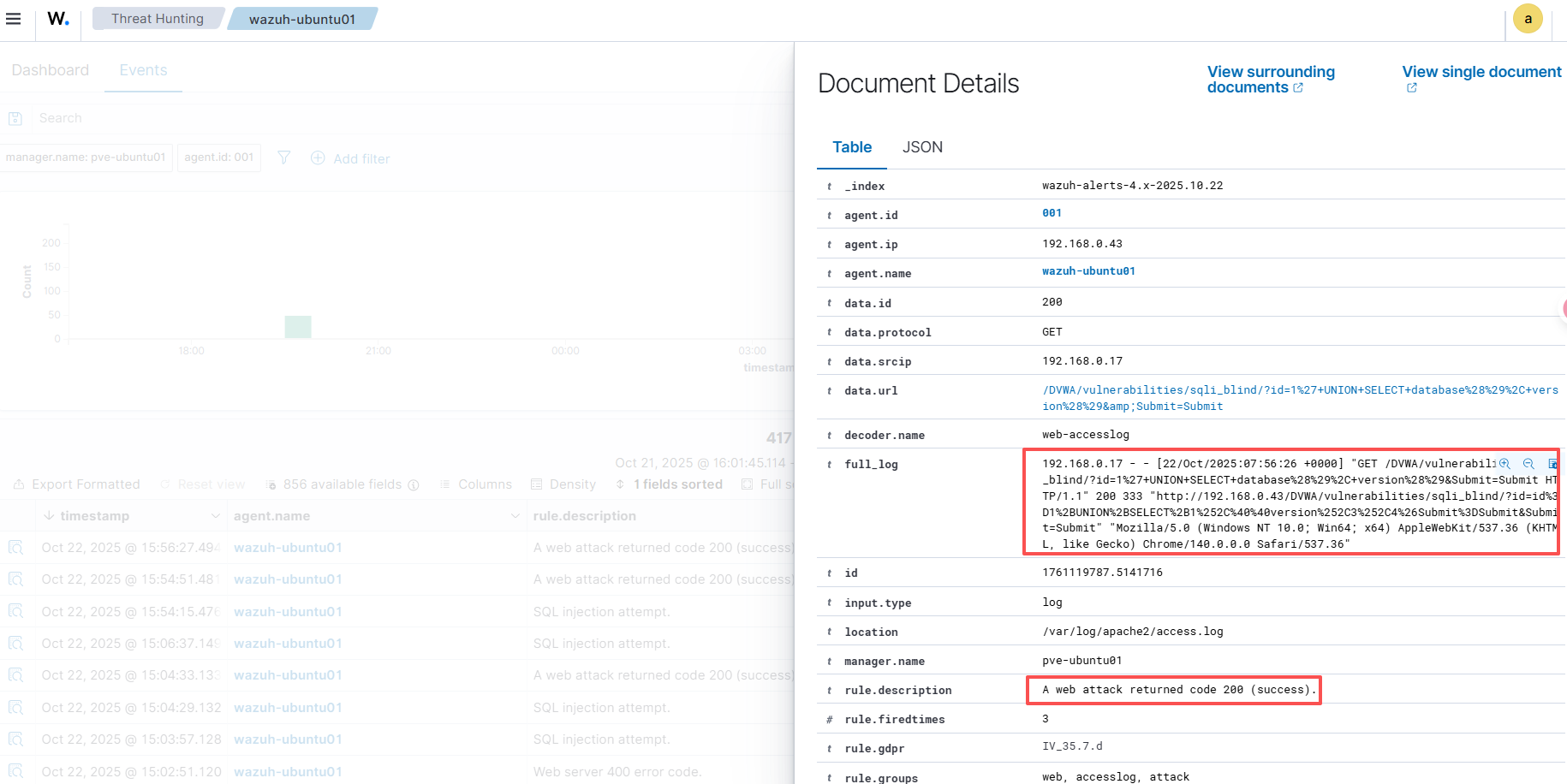
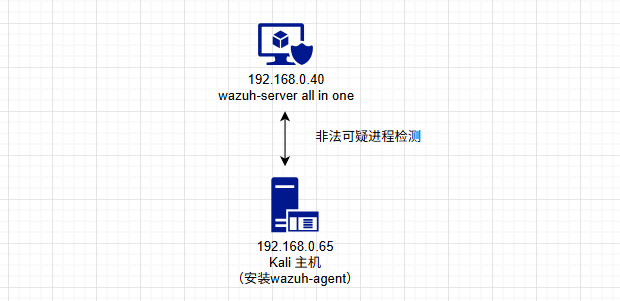



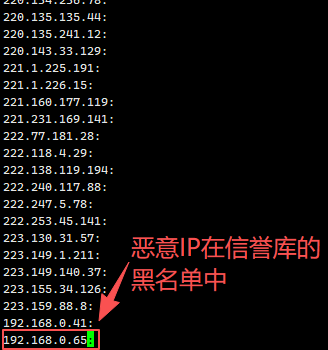

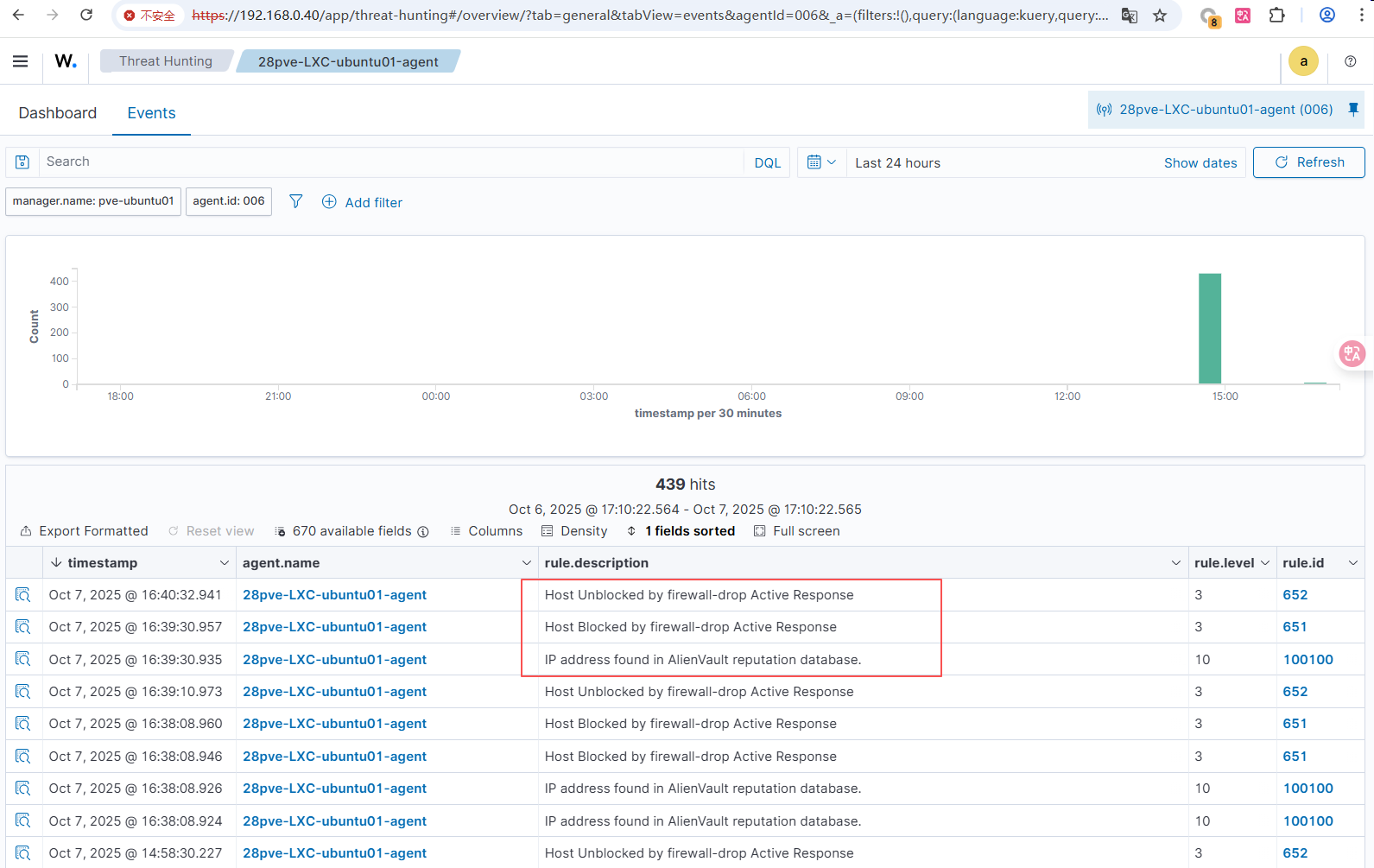

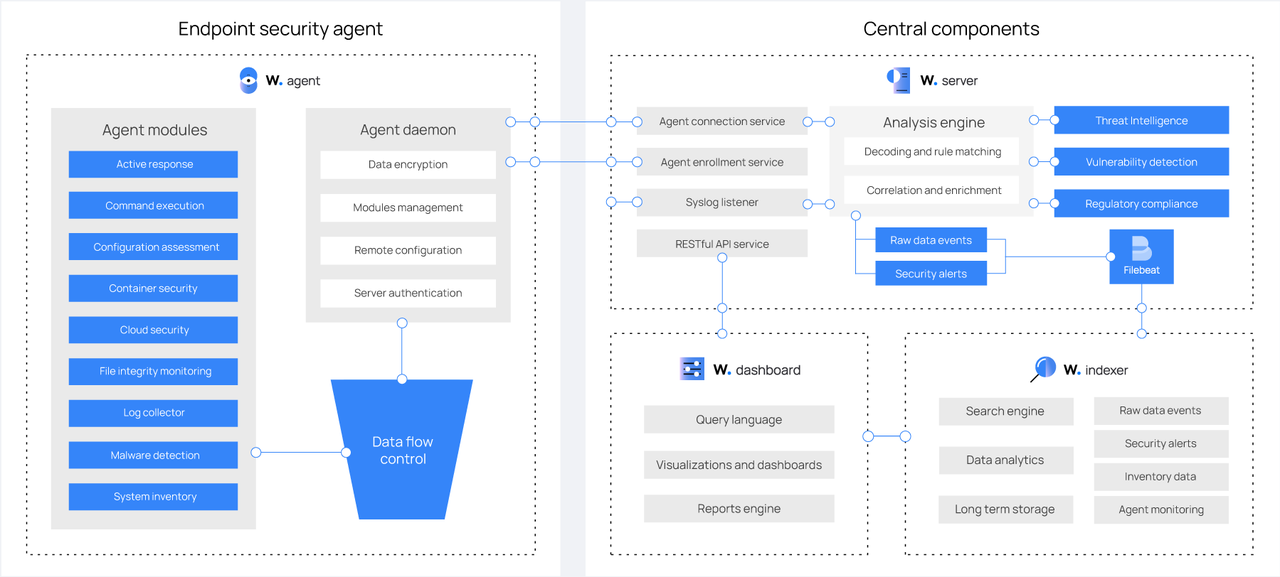

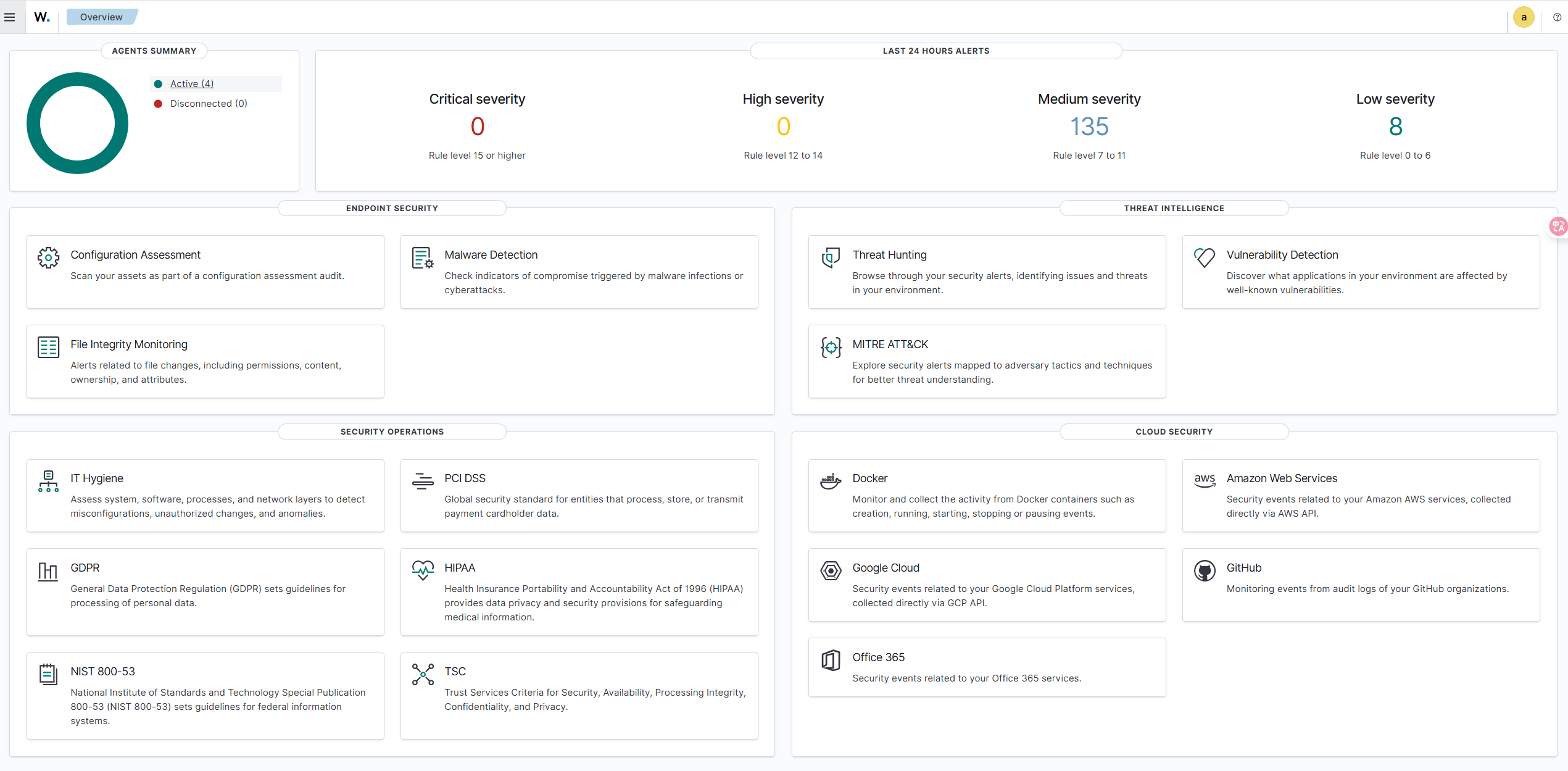
![\[图片\]](http://image2.ishareread.com/images/2025/20250929/4-wazuh%E7%9A%84endpoints.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250929/5-wazuh%E7%9A%84%E6%96%B0%E5%A2%9Eagent.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250929/6-wazuh%E8%87%AA%E5%8A%A8%E7%94%9F%E6%88%90agent%E5%AE%89%E8%A3%85%E8%84%9A%E6%9C%AC.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250929/7-wazuh%E5%AE%89%E8%A3%85.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250929/8-wazuh%E5%AE%89%E8%A3%85agent%E5%90%AF%E5%8A%A8%E7%8A%B6%E6%80%81.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250929/9-wazuh%E5%AE%89%E5%85%A8%E9%A3%8E%E9%99%A9%E6%A6%82%E8%A7%88.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250830/1-%E9%A3%9E%E7%89%9Bnas-docker.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250830/2-easytier-docker%E9%AB%98%E6%9D%83%E9%99%90%E9%85%8D%E7%BD%AE.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250830/3-easytier-docker%E5%91%BD%E4%BB%A4%E9%85%8D%E7%BD%AE.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250830/4-easytier-window%E7%BB%84%E7%BD%91.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250830/5-easytier-window%E7%BB%84%E7%BD%91%E6%88%90%E5%8A%9F.png)
![\[图片\]](http://image2.ishareread.com/images/2025/20250830/6-easytier%E7%BB%84%E7%BD%91%E6%95%88%E6%9E%9C.png)